
Generating faces from emojis with stylegan and pulse
- A quick example
- Emojis instead of photographs
- The people behind the emojis
- Per category
- Artifacts
- Babies
- Bald emojis
- Bearded faces
- Brides
- Cooks
- Curly hair
- Earrings
- Elves
- Face contour
- Sad facial expressions
- Santa Claus
- Skin colour
- Surprise expressions
- Wrinkles and expression lines
- Massaging hands
- Health workers
- Glasses
- Male teachers (and more glasses)
- Old age
- Young age
- Steamy pictures
- Head accessories
- Left and right weight
- Vampires
- Skulls
- Nonhuman
- Failures
- Per category
- Limitations and biases
- The code
- Coda
- Thanks for reading
There has been a lot of improvement in GANs 1 in the last years. One of the many uses has been to upscale blurry images.
The GAN 1 generates a realistic face based on the training on all the faces it has seen. This, which looks like an enhance CSI joke, is of course not reconstructing the original image that information is not there in the low resolution image). It is extrapolating how an image could look like.
A quick example
We use the image of Lena 2 and downscale it with a script. Check the end of the article for all the code.



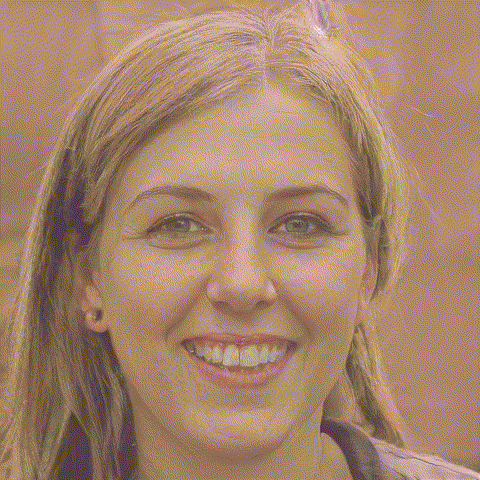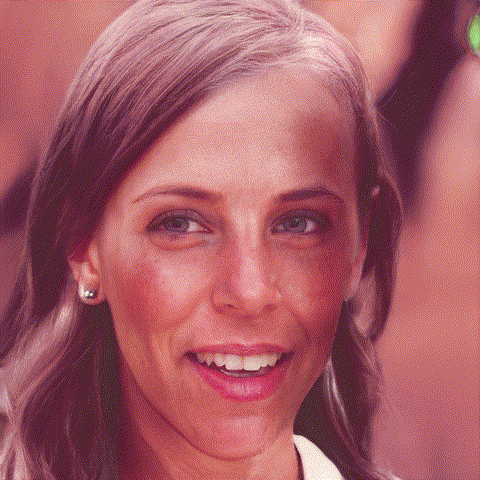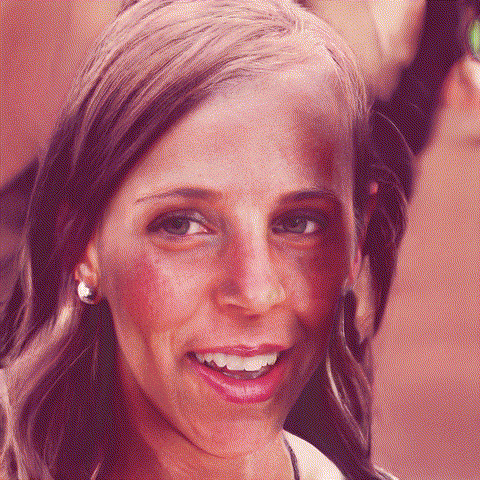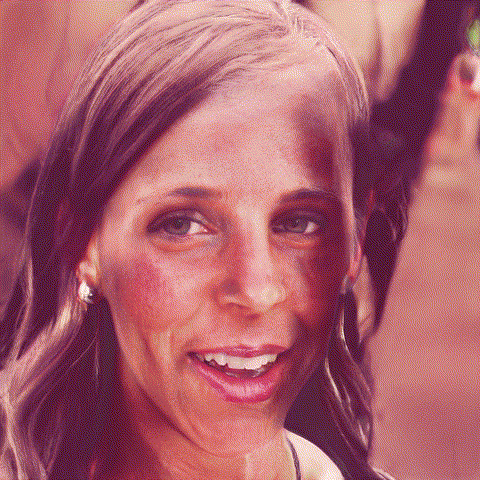
Two examples of generating plausible images from downscaled photos. Downscaling more (16x16px, top) gives more room for interpretation than a higher resolution (32x32px, bottom)
Emojis instead of photographs
We know this has decent results — like in the example above — with downscaled photos. How good would it be with stylized characters? Will it interpret the features correctly?
We have run the generator on all the emojis. From al the ones recognized as a face the generation has been performed and included in the image below.

All the emojis and the generated images in a single image. Left, emoji; right, generated image. Only includes emojis identified as a face 3. You can find the full 20MB image on the github repository as well.
The people behind the emojis
We ran every emoji, for different platforms, through the GAN 1. These are the results for all emojis recognized as a face 3. The emojis that were not recognized are ommited. Following, a selection of interesting examples.
(For more detailed examples, check the Per category; for a selection of failures click here)

The dense eyebrows, blushed cheeks and the matching smile all remind strongly of the original emoji.





A plain good example of image generation. There are hints of a moustache as well.

The expression — in nose, mouth and cheeks — is capturing very well the original emoji.

The resulting face has a tortured expression. There appears to be a strong bias in favour of smiling. This is a perfect example of it.



When supplied with multiple images the align_faces.py command will have selected one. In this case, the bottom left girl.
This one is provided as an example of the numerous multiple people emoji.


Per category
Artifacts

A pretty good result. We can see a shiny blob — next to the ear — as an artifact in a lot of the pictures. During then generation this blob changes and usually ends up assimilated in features (sometimes, it ends up as earrings) You can see an example of this in the animation above.

Example of artifacts that are generated. They have the shape of blobs and are often shiny.
Babies

Here we can observe many different things in a single image:
- The data does not include a lot of bald or alternative hairstyles examples. Neither does it contain 4, understandably, halos
- The halo seems to widen the hair area, resulting in a wide area of hair.
- the lighter face borders seem to merge with the background and result in a wider face (see chin area and compare with next)

A more defined edge seems to merge less with the background during the downscaling process and causes more stylized features.
Bald emojis
As with other examples, not a single bald face was generated while generating images for this article. We can see in the following images how the shape is similar, but it is always — in all the images we generated — covered with hair.






Bearded faces
Beards also do not seem to be generated. Below we can see examples of how they are interpreted as shadows or double chins.

The densest beard generated.

Beards seem to “reserve” the space for the beard. We can see some hairs in the beard area, but they are closer to 1 day without shaving than to a full beard. Could this be, as with the smiles, because people in the training dataset were mostly clean-shaven?

Beard interpreted as a shadowed area under the chin.

Another example of shadow.

Here the beard has been interpreted as a double chin.

Another example of double chin.

A beard interpreted as shadow, and not part of the face.
Brides

It seems the veil merges with the background, and it gets ignored completely. The darker lips also seem not to have been picked up on.

What can I say? This seems to have generated a bride’s stalker out of a computer’s nightmare. The combination of very dark hair and the white veil — interpreted here as light — generates a dramatic effect. The result, combined with the strange smile, is a bit uncanny.

Still creepy, but less dramatic.

Notice pointy elf ears. This is remarkable; the training data could not have a lot of those. The diadem resulted in some horizontal wrinkle across the forehead. It seems generating shape different from the examples is easier than producing new features — hair, accessories, etc.
Additionally, the generated shirt follows a similar patch pattern as the one in the emoji.
Cooks
We can see how caps and accessories are not often present in the training dataset. A cook’s hat has been interpreted here as white hair, with pretty convincing results.
We can also notice how the moustaches are interpreted as “reserved space”, or as a slighly more hairy area, but not as a full moustache or bear, an indication that probably they were also absent in training. Same space is reserved in the toque’s white area. This produces an ample forehead.

The moustache area is “reclaimed”. Only with an unshaven look, instead of a full moustache.

Nothing like the recipes of aunt Dorothy.
Curly hair
Curly hair from emojis is not correclt reproduced. It could be because the curly hair in an emoji is overly stylized and unrealistic, or for lack of training examples. We can only speculate about it. Belowe some examples:
The results are similar for different hair and skin colours:




Skin colour does not seem to make a difference in the generated image curl.

This is one of the best looking examples and the hair is only wavy.

Another example where the hair is a bit messy, but still not close to the depicted one.
Earrings

Although the training data does not seem to include a lot of accessories, earrings appear often. They must have been a common ocurrence in the training examples 4.
Elves
A few more elves examples below. We can see the lower ear lobes have been reintepreted as hair or long earrings. The reptile-like pattern of the shirt is surprisingly consistent. The ears are — as it would be expected — pointy.



Face contour

A very good result. Notice the double chin and the very soft contour.

A bit harder contour; a bit less pronounced double chin.

With a very well defined contour the double chin disappears.
Sad facial expressions








Santa Claus

Finally, the man behind Santa Claus is revealed.


Skin colour

The model performs worse with darker colour skin. This has been addressed in the project’s paper 5. It generates an image with lower saturation, or with exposure problems instead.

The GAN 1 gets very confused with darker-skin emojis.
Surprise expressions

The model also seems to have mostly lightly smiling faces. More extreme expressions are usually interpreted as a bigger area of the surrounding “material”. Here, for instance, we can see the chin are becomes larger, while the mouth itself is the usual size.

The same increase in height in the chin area. Additionally, glasses were generated. Maybe because of the strong contour around the eyes.
Wrinkles and expression lines

A very clear and unproblematic example. We can see how, even with very smooth gradients in the skin, the GAN 1 tends to generate wrinkles and expression lines.
Massaging hands
In the following examples the hands around the head seem to have been interpreted as part of the face, producing a long forehead. The relaxed faces produced reflect very well th emojis expression.


Ecstatic after a relaxing head massage




Health workers

An honest young doctor. Thanks to all our health workers.

We again notice the space reserved for the moustache.


Glasses
In 2 out of 3 graduated emojis the Neural network has generated glasses that were not there in the emoji (!). I find that startling. Might be that we are reading too much into it.

Imagined glasses taht were never there

Another example. Is this a coincidence or is it derived from the academic accessories?

An exception where glasses were not generated.

It seems the strong contour caused glasses to be imagined. Same example as this
Male teachers (and more glasses)
Here we have the opposite case as in the previous example: Glasses present in the emoji have disappeared in the generated faces.
In addition to this, we can notice how the blackboard in the background shapes the haircur of the generated faces.

No glasses.

Short in the lower part, long at the top.

Another example of no glasses.

No glasses.

No glasses and slightly drowsy.


Old age
This is a selection of some of the best images generated from an image representing an old person.






Young age
Some of the emojis generated images with younger characters. One specific style of emoji generated all the younger-looking images. I ignore if this is due to the random seed, or if something in the colours makes it more favourable.


Glasses did not appear, and grandma is a bit younger.


Steamy pictures
To my surprise, the GAN 1 recognized very consistently images where there was a glow or a steam, and generated accorddinly diffuse images.


Head accessories
Crowns
Crowns are probably not part of the training set — my wild guess. Instead of appearing in the resulting image, they seem to worsen the lighten conditions of the generated image.


Diadems
Diadems have a similar result as crowns. They are also not generated.

Hats


Headscarves
The generated images never generate a hair accessory — including headscarves. The rest of the generation is still believable.


Helmets


Red hair




Turbans
Most turban-wearing emojis seem to generate more skin surface. This translates in big foreheads and receding hairlines.




Left and right weight
The original image can influence if the generated image will be a frontal or a three quarter angle. We can see a good example of this in asymmetric source images, such as the emojis in the tipping hand and raising hand category. From the generated images they are more likely — not always — to weight more on the side where the raised hand was.



More weight on the left or the right side tends to generate most of the face in that area. This creates a three quarter view, instead of a frontal one.

Sometimes even symmetric emojis — like in this example — generate a three quarter view.
Vampires
With the vampire emojis as source we observe an interesting effect: it seems ears and teeth get shaped into the source image shape, while other attributes — eye colour — do not adapt as easily.

The eyes did not become red, but the canine teeth did enlarge to match the source. The ears are also bigger than usual.

Another example of canine teeth.
Skulls


Creepy, and surprisingly similar. The width of the teeth is almost exact.
Nonhuman

Some of the non-face emojis recognized as faces produce interesting results.

Some emojis — like this hearing aid — were interpreted as a face after downscaling.


Failures
Here is a summary of the main failures we ran into when feeding emojis as input. Probably some of these do not occur when using photographic images and others do.
The GAN 1 gets very confused with darker-skin emojis.

An example of the neural network hallucinating a whiter person.

In some cases the artifacts are very noticeable. Usually it is solved with more iterations or a different seed value — randomly selected if not specified. Notice also the excessive wrinkles and expression lines the generated image tends to have.

Moustache space is “reserved” but not populated with appropriate hair density. The head hair is often influenced by random background elements or contours.

Due to the highly stylized emojis, the gender is very often not matching the input emoji.

The GAN 1 produces images with lower saturation and bad lighing conditions when fed emojis with darker colours.


Facial expression are not reproduced in the generated image. It seems to assume a mild smile — we assume because of training data 4.
Limitations and biases
There are always biases based on the data used for training. This is a limitation of learning by example. While not a criticism, it is useful to be aware of what the biases of a specific model are. The authors of pulse very wisely acknowledge these biases 5. In this article this has less relevance, since we are not ven using photographies but stylized icons — emojis — as an investigation, which will have their own biases in how they are stylized.
In this case we can speculate that the training did not include many cases of:
- dark-skinned people
-
Different ages
The training set does not seem to include very young people or babies.
-
hair
- hair other than wavy or straight
- bald people
- red hair
-
beards, moustaches
Moustaches produce a bigger space and some hair, but nothing too dense. I would guess training data consists mostly of clean-shaven or hairless subjects. In addition to this, we are using emojis as input — and not photographies — and it is very likely in most emojis the stylized version of hair has a very slight semblance to real hair.
- helmets, caps, hats, headscarves, turbans, crowns, diadems
-
accessories, except earrings and glasses
-
non-smiling faces
The faces generated are trying very hard to smile. Sometimes they result in a quirky half smile. This might be a cultural phenomenon in the training data — smiling when a photo is to be taken.
The code
If you would like to reproduce the examples above or play with new ones.
Cloning the repo
git clone https://github.com/adamian98/pulse
Installing dependencies
The pulse repository 6 has instructions to install dependencies with conda. If you prefer virtualenv the following might be useful.
cd pulse
# install dependencies
sudo apt-get install python3.8-dev
sudo apt install libpython3.8-dev
virtualenv -p /usr/bin/python3.8 newenv3
./newenv3/bin/pip install certifi cffi chardet cryptography \
cycler idna intel-openmp kiwisolver matplotlib mkl install numpy \
olefile pandas pillow pycparser pyopenssl pyparsing pysocks \
python-dateutil torch pytz readline requests scipy tk torchvision \
tornado urllib3 wheel zstd dlib
Running
There are two main scripts we need to use:
-
align_face.pysets all the images in the input folder in the right format and downscales them to the desired size. The less resolution — more downscaling — the more room the GAN 1 has to reconstruct the high resolution image. -
run.pygenerates the prediction and — optionally — saves the intermediate steps. This can be useful to generate animations such as the one picturing Lena at the beginning of this article.
Running (16px downscale)
# align face in image and downscale to resolution (16px)
./newenv3/bin/python align_face.py -input_dir 'lena_input_folder_16px' -output_size=16
# by default, downscaled images go to the `pulse/input`folder
# you might clear that of other images
# make the prediction and output intermediate stesps
./newenv3/bin/python run.py -output_dir='output_16' -save_intermediate -steps=200
Running (32px downscale)
# align face in image and downscale to resolution (32px)
./newenv3/bin/python align_face.py -input_dir 'lena_input_folder_32px' -output_size=32
# by default, downscaled images go to the `pulse/input`folder
# you might clear that of other images
# make the prediction and output intermediate stesps
./newenv3/bin/python run.py -output_dir='output_32' -save_intermediate -steps=200
Default folders and options
As stated above, some folders — like pulse/input are specified by default.
We cans see a list of all the default options and folders in the original source code:
For align_face.py:
parser.add_argument('-input_dir', type=str, default='realpics', help='directory with unprocessed images')
parser.add_argument('-output_dir', type=str, default='input', help='output directory')
parser.add_argument('-output_size', type=int, default=32, help='size to downscale the input images to, must be power of 2')
parser.add_argument('-seed', type=int, help='manual seed to use')
parser.add_argument('-cache_dir', type=str, default='cache', help='cache directory for model weights')
Source at https://github.com/adamian98/pulse/blob/master/align_face.py
For run.py:
#I/O arguments
parser.add_argument('-input_dir', type=str, default='input', help='input data directory')
parser.add_argument('-output_dir', type=str, default='runs', help='output data directory')
parser.add_argument('-cache_dir', type=str, default='cache', help='cache directory for model weights')
parser.add_argument('-duplicates', type=int, default=1, help='How many HR images to produce for every image in the input directory')
parser.add_argument('-batch_size', type=int, default=1, help='Batch size to use during optimization')
#PULSE arguments
parser.add_argument('-seed', type=int, help='manual seed to use')
parser.add_argument('-loss_str', type=str, default="100*L2+0.05*GEOCROSS", help='Loss function to use')
parser.add_argument('-eps', type=float, default=2e-3, help='Target for downscaling loss (L2)')
parser.add_argument('-noise_type', type=str, default='trainable', help='zero, fixed, or trainable')
parser.add_argument('-num_trainable_noise_layers', type=int, default=5, help='Number of noise layers to optimize')
parser.add_argument('-tile_latent', action='store_true', help='Whether to forcibly tile the same latent 18 times')
parser.add_argument('-bad_noise_layers', type=str, default="17", help='List of noise layers to zero out to improve image quality')
parser.add_argument('-opt_name', type=str, default='adam', help='Optimizer to use in projected gradient descent')
parser.add_argument('-learning_rate', type=float, default=0.4, help='Learning rate to use during optimization')
parser.add_argument('-steps', type=int, default=100, help='Number of optimization steps')
parser.add_argument('-lr_schedule', type=str, default='linear1cycledrop', help='fixed, linear1cycledrop, linear1cycle')
parser.add_argument('-save_intermediate', action='store_true', help='Whether to store and save intermediate HR and LR images during optimization')
Source at https://github.com/adamian98/pulse/blob/master/run.py
Coda
I hoped you liked it. This was a selection of the generated images. You can check all the emoji-source — generated image pairs in the github repository:
Thanks for reading
Footnotes
-
https://en.wikipedia.org/wiki/Lenna A commonly-used test image for image processing. ↩
-
by
align_faces.py. see Running the code ↩ ↩2 -
I want to make clear we do not have access to the training data. When we refer to the training data containing or not containing examples, we are only talking about the likelihood and abundance of it based on the results we generated for the source emojis. This is made explicit in some instances. Sometimes — for the benefit of the reader — we do not repeat it. For those cases please assume this meaning. ↩ ↩2 ↩3
-
Biases were addressed in an updated section of the paper https://arxiv.org/pdf/2003.03808.pdf ↩ ↩2