
Statistical grammar: guessing a german noun's gender
Go here for a simple listing of the gender rules in german
in german there are 3 genders: masculine, feminine, neutral, der; die; das. You need to memorize which words are which gender, since it affects certain constructions. The accusative, dative forms, for instance, can be different according to the noun’s gender.
A quick example, with accusative:
Er trinkt ein Bier: Bier is neutral.
Er trinkt einen Kaffee Kaffee is masculine. Notice the -en.
There is no escape: you need to learn — or guess — the noun’s gender.
It gets easier with a combination of time and some rule-of-thumb laws, or heuristics.
A heuristic is any approach to problem solving or self-discovery that employs a practical method that is not guaranteed to be optimal, perfect or rational, but which is nevertheless sufficient for reaching an immediate, short-term goal.
Where finding an optimal solution is impossible or impractical, heuristic methods can be used to speed up the process of finding a satisfactory solution. Heuristics can be mental shortcuts that ease the cognitive load of making a decision 1.
Mental shortcuts to ease the cognitive load… sounds like something useful to learn a language! (all those pesky cases, vocabulary and pronunciation already take a lot of my cognitive load). Let’s see how good those heuristics are and if we can come up with easier ones that apply in most cases.
The data
We have at our disposal a list of the 500.000 most frequent words 2 in german and their genders
The file is a csv without a header and begins like this:
| word | gender |
|---|---|
| ich | n |
| ist | n |
| es | n |
| was | m |
| ich | n |
| ist | n |
| es | n |
| was | m |
| wie | n |
| ja | n |
| so | m |
| aber | n |
| haben | n |
| da | n |
| nein | n |
| noch | m |
| habe | f |
| hast | f |
| aus | n |
| gut | n |
| jetzt | n |
| sein | n |
| mal | n |
| als | m |
| oder | f |
| nichts | n |
| wo | n |
| werden | n |
| mehr | n |
| warum | n |
| bitte | f |
| etwas | n |
| muss | n |
| los | n |
| … | … |
The first lines of the data. Genders are shorthanded as m, f, n.
Textbook heuristics: the rules of the game
We want a rule that:
- can be applied mechanically (no countries are masculine and similar rules. We want a simple rule, not more things to memorize!) 3 Examples are things like boat names are feminine.
- Also not interested in learning exceptions. We want the simplest mechanical rule that guesses right the most. We will ignore all the rules that are not mechanical (names of ships are feminine… ok), since we do not want to teach a program what is a ship and what not.
| Singular form ending in | ||
|---|---|---|
| Masculine | Feminine | Neutral |
| -ich | -ei | -chen |
| -ig | -in | -lein |
| -ling | -heit | -icht |
| -s | -keit | -tel |
| -and | -schaft | -tum |
| -ant | -ung | -eau |
| -är | -a | -ett |
| -ast | -ade | -in |
| -eur/-ör | -age | -ing |
| -(i)ent | -aise/-äse | -(i)um |
| -ier | -aille | -ma |
| -iker | -ance | -ment |
| -ismus | -äne | |
| -ist | -anz | |
| -or | -elle | |
| -ence | ||
| -ette | ||
| -euse | ||
| -ie | ||
| -(i)enz | ||
| -(i)ere | ||
| -ik | ||
| -ille | ||
| -ine | ||
| -ion/-ation | ||
| -isse | ||
| -(i)tät | ||
| -itis | ||
| -ive | ||
| -ose | ||
| -sis/-se | ||
| -ur | ||
| -üre |
Textbook rules 4
Distribution of genders
Because of this we cannot rely on averages to summarize (in fact, averages are often, like piecharts, a bad idea to analyse data). It is a good idea to look at the distribution of the data.
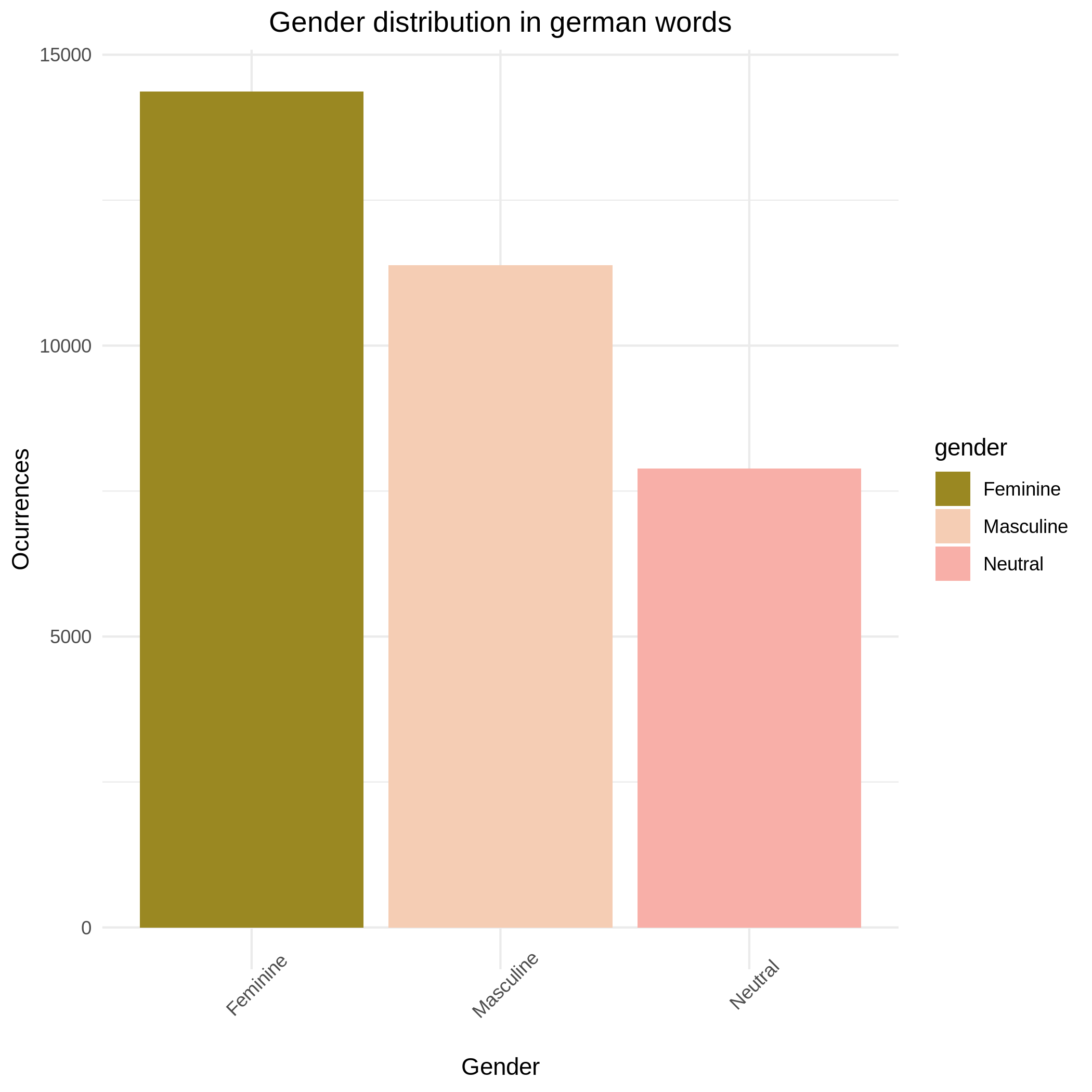
Based on the 500.000 most common german words
The baseline: textbook heuristics
Let’s apply the heuristic rules of our grammar book to our data and see how accurate they are. We will guess the gender according to the textbook rules:
Some rules are pretty short (ending in a single letter). Are there internal contradictions?
We can see that some words match several of the rules at the same time!: Some examples of multiple matches are:
-
-incan be both feminine and neutral Automatically any word ending in-in, according to the textbook heuristics is probably feminine. But it is also probably neutral (see table above), since it has exactly the same rule! We will ignore this-inending rule -
-itis(feminine ending),-s(masculine ending) Both match
Whenever there are multiple matches we will match the longest one (in number of characters) only. Once we apply this we get rid of cases with multiple matches
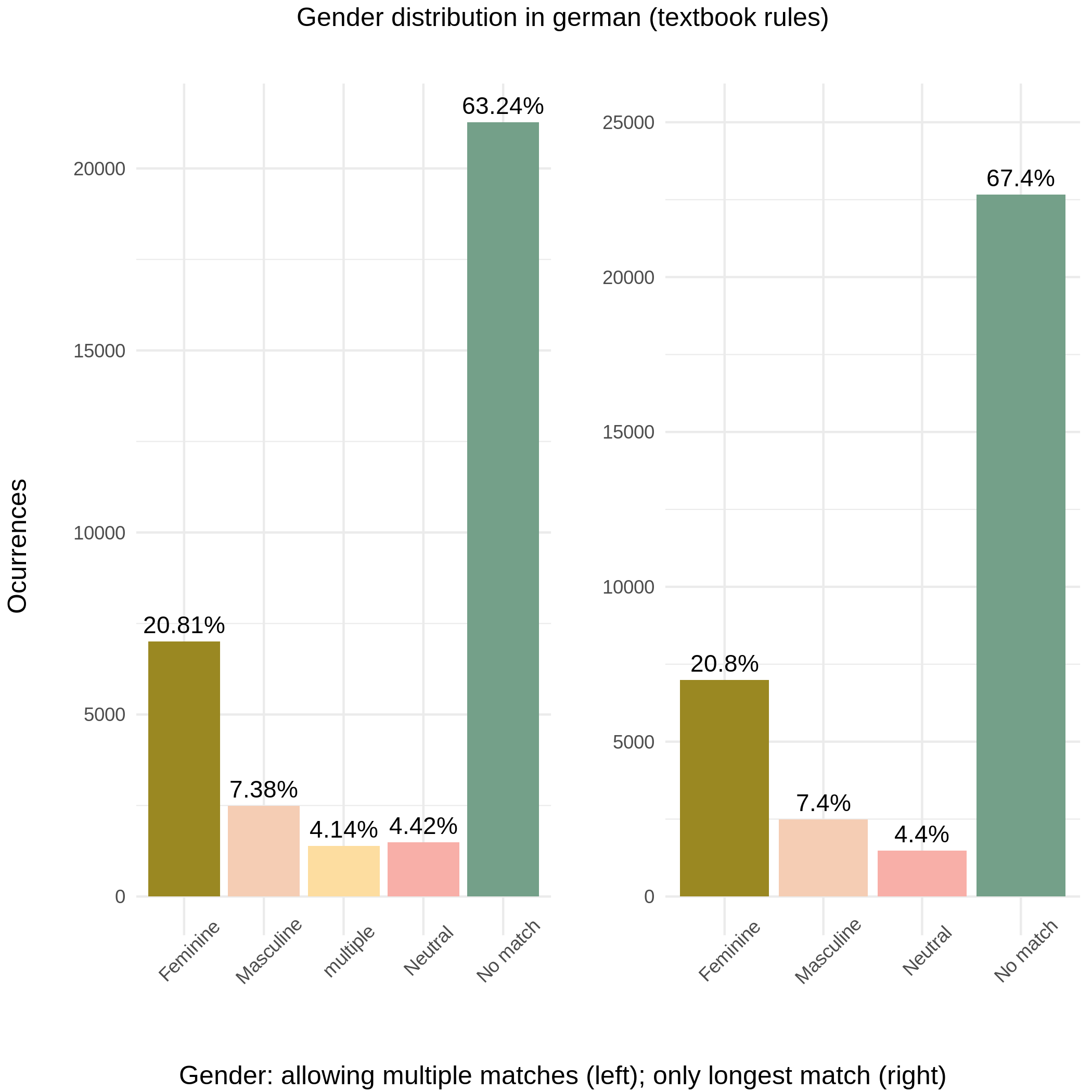
Who is bad at grammar now
We can see now that the distribution is similar to our first chart (figure 1)
There are more feminine nouns, followed by masculine and neutral.
That huge last bar is a problem, though: a lot of the words did not match any rule!
No match
Our only problem now is we still have a lot of words without any heuristic we can apply. This is not good for our cognitive load, remember? We will deal with this in a second, but first, how accurate are the results that do match?
Accuracy
How accurate is the classification of the words that matched a rule? Let’s find out:
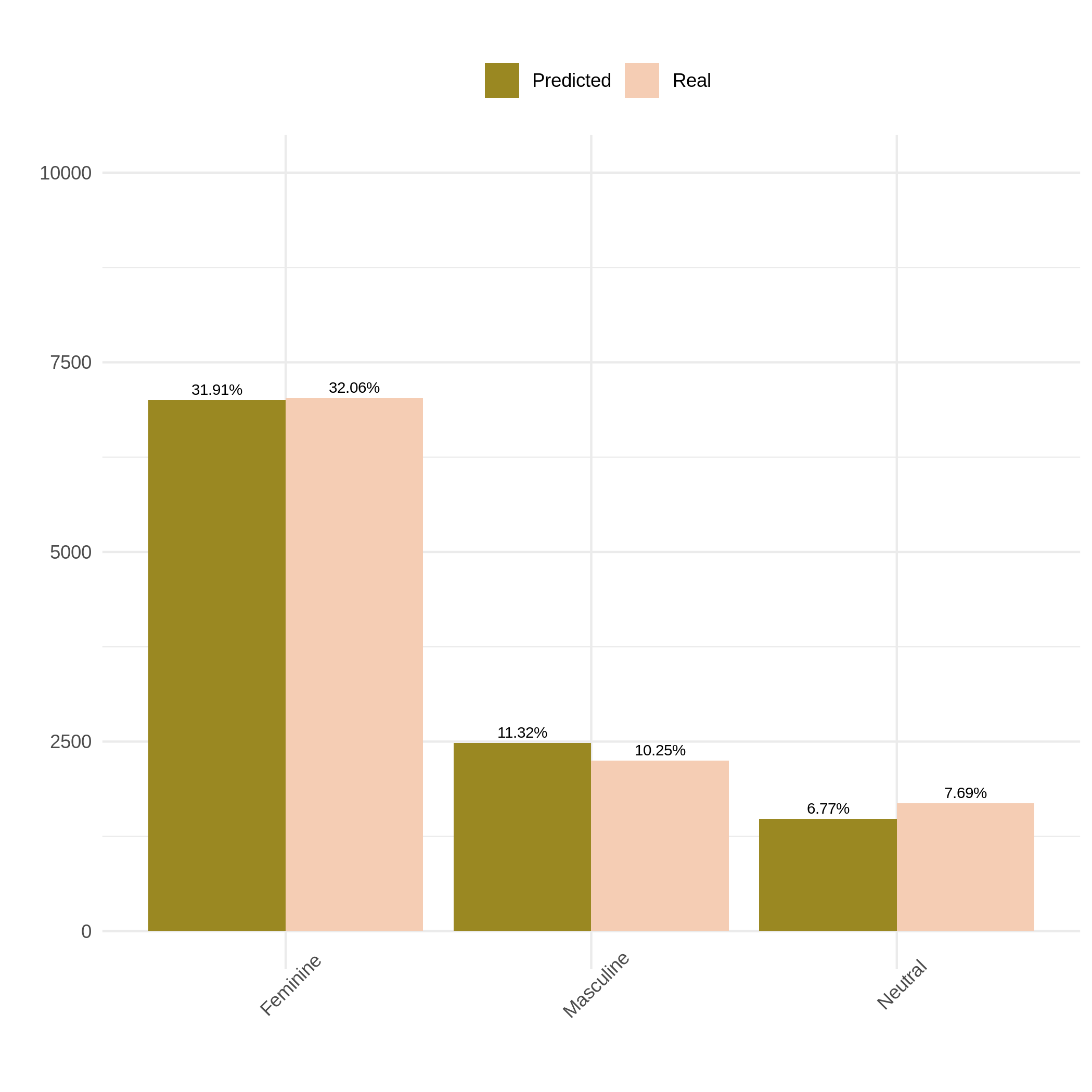
Very good accuracy
This will be our baseline for, you guessed it, our quest to find a better rule.
Finding a better rule
Groups of n characters
Is there a group of n characters in a noun that correspond to a particular gender?
We will test all the permutations from 2 to 4 letters containing, starting or ending in the string.
All 4 character permutations of the 30 letters a b c d e f g h i j k l m n o p q r s t u v w x y z ß ü ö ä
means we are dealing with = 657,720 permutations.
We will discard groups that match less than 1% of the time, to avoid having a huge list of values. We are looking at words that start, end , or contain each group of characters.
An inefficent implementation, and 21 hours later the program has finished. What are the results?
Removing rules inconsistency
Some rules match all genders. 5 We remove these duplicates and get our data to start looking for useful rules.
Here is the full table, ordered by Gender matched, Percent matched, Match type and Num matched:
| Gender matched | Value matched | Num matched | Percent matched | Match type |
|---|---|---|---|---|
| n | en | 2819 | 0.35746893228506216 | contain |
| n | er | 2254 | 0.28582297742835405 | contain |
| n | en | 1874 | 0.23763631752472736 | end |
| n | ch | 1820 | 0.2307887395384225 | contain |
| n | te | 1228 | 0.15571899568856198 | contain |
| n | ge | 1058 | 0.13416180573167638 | contain |
| n | ei | 1045 | 0.13251331473497338 | contain |
| n | re | 918 | 0.11640882576718235 | contain |
| n | el | 913 | 0.11577479076845044 | contain |
| n | in | 908 | 0.1151407557697185 | contain |
| n | sc | 898 | 0.11387268577225462 | contain |
| n | sch | 890 | 0.11285822977428354 | contain |
| n | st | 885 | 0.1122241947755516 | contain |
| n | ie | 877 | 0.11120973877758053 | contain |
| n | he | 785 | 0.09954349480091301 | contain |
| n | au | 716 | 0.09079381181841238 | contain |
| n | an | 671 | 0.08508749682982501 | contain |
| n | se | 664 | 0.08419984783160031 | contain |
| n | le | 627 | 0.07950798884098402 | contain |
| n | be | 621 | 0.07874714684250571 | contain |
| n | de | 586 | 0.0743089018513822 | contain |
| n | ra | 585 | 0.07418209485163581 | contain |
| n | er | 577 | 0.07316763885366473 | end |
| n | la | 566 | 0.07177276185645448 | contain |
| n | nd | 565 | 0.07164595485670809 | contain |
| n | es | 549 | 0.06961704286076592 | contain |
| n | me | 548 | 0.06949023586101953 | contain |
| n | ng | 533 | 0.06758813086482374 | contain |
| n | et | 512 | 0.06492518387014963 | contain |
| n | al | 508 | 0.06441795587116407 | contain |
| n | nt | 490 | 0.06213542987572914 | contain |
| n | ri | 480 | 0.060867359878265276 | contain |
| n | ter | 477 | 0.06048693887902613 | contain |
| n | ha | 470 | 0.05959928988080144 | contain |
| n | is | 461 | 0.05845802688308395 | contain |
| n | fe | 460 | 0.05833121988333756 | contain |
| n | che | 460 | 0.05833121988333756 | contain |
| n | it | 451 | 0.05718995688562008 | contain |
| n | um | 451 | 0.05718995688562008 | contain |
| n | un | 451 | 0.05718995688562008 | contain |
| n | us | 437 | 0.05541465888917068 | contain |
| n | at | 434 | 0.05503423788993152 | contain |
| n | or | 433 | 0.054907430890185134 | contain |
| n | ar | 432 | 0.05478062389043875 | contain |
| n | ne | 426 | 0.05401978189196044 | contain |
| n | hen | 420 | 0.05325893989348212 | contain |
| n | ze | 393 | 0.0498351509003297 | contain |
| n | ste | 393 | 0.0498351509003297 | contain |
| n | il | 383 | 0.048567080902865836 | contain |
| n | li | 382 | 0.04844027390311945 | contain |
| n | ro | 379 | 0.0480598529038803 | contain |
| n | tr | 379 | 0.0480598529038803 | contain |
| n | ic | 378 | 0.04793304590413392 | contain |
| n | we | 372 | 0.0471722039056556 | contain |
| n | ns | 362 | 0.04590413390819173 | contain |
| n | as | 359 | 0.045523712908952574 | contain |
| n | ti | 355 | 0.04501648490996703 | contain |
| n | on | 351 | 0.04450925691098149 | contain |
| n | hen | 344 | 0.04362160791275679 | end |
| n | eb | 342 | 0.04336799391326402 | contain |
| n | ke | 340 | 0.04311437991377124 | contain |
| n | ve | 339 | 0.042987572914024864 | contain |
| n | ta | 331 | 0.041973116916053765 | contain |
| n | sp | 329 | 0.04171950291656098 | contain |
| n | chen | 322 | 0.04083185391833629 | contain |
| n | am | 318 | 0.04032462591935075 | contain |
| n | ier | 318 | 0.04032462591935075 | contain |
| n | ht | 316 | 0.04007101191985798 | contain |
| n | sc | 315 | 0.03994420492011159 | begin |
| n | ich | 313 | 0.03969059092061882 | contain |
| n | sch | 312 | 0.03956378392087243 | begin |
| n | cht | 310 | 0.03931016992137966 | contain |
| n | um | 308 | 0.039056555921886886 | end |
| n | ma | 307 | 0.0389297489221405 | contain |
| n | ren | 302 | 0.038295713923408574 | contain |
| n | ab | 294 | 0.03728125792543748 | contain |
| n | mi | 292 | 0.037027643925944716 | contain |
| n | ver | 292 | 0.037027643925944716 | contain |
| n | rn | 289 | 0.03664722292670555 | contain |
| n | eh | 283 | 0.03588638092822724 | contain |
| n | hr | 283 | 0.03588638092822724 | contain |
| n | rt | 283 | 0.03588638092822724 | contain |
| n | ts | 283 | 0.03588638092822724 | contain |
| n | ein | 283 | 0.03588638092822724 | contain |
| n | em | 280 | 0.035505959928988085 | contain |
| n | na | 280 | 0.035505959928988085 | contain |
| n | el | 277 | 0.03512553892974892 | end |
| n | ac | 277 | 0.03512553892974892 | contain |
| n | aus | 276 | 0.03499873193000254 | contain |
| n | ko | 275 | 0.03487192493025615 | contain |
| n | gs | 274 | 0.034745117930509765 | contain |
| n | ge | 271 | 0.03436469693127061 | begin |
| n | ten | 269 | 0.034111082931777836 | contain |
| n | ent | 267 | 0.03385746893228506 | contain |
| n | ck | 266 | 0.03373066193253866 | contain |
| n | chen | 259 | 0.03284301293431397 | end |
| n | ni | 259 | 0.03284301293431397 | contain |
| n | ec | 257 | 0.032589398934821205 | contain |
| n | si | 257 | 0.032589398934821205 | contain |
| n | ch | 253 | 0.03208217093583566 | end |
| n | ol | 253 | 0.03208217093583566 | contain |
| n | rs | 250 | 0.0317017499365965 | contain |
| n | ld | 247 | 0.03132132893735734 | contain |
| n | and | 244 | 0.03094090793811818 | contain |
| n | ka | 242 | 0.03068729393862541 | contain |
| n | bi | 240 | 0.030433679939132638 | contain |
| n | to | 239 | 0.03030687293938625 | contain |
| n | gen | 239 | 0.03030687293938625 | contain |
| n | fa | 237 | 0.030053258939893482 | contain |
| n | pe | 235 | 0.029799644940400712 | contain |
| n | eu | 234 | 0.029672837940654326 | contain |
| n | sen | 234 | 0.029672837940654326 | contain |
| n | men | 232 | 0.029419223941161563 | contain |
| n | ot | 228 | 0.028911995942176007 | contain |
| n | wa | 227 | 0.028785188942429624 | contain |
| n | st | 225 | 0.02853157494293685 | begin |
| n | ngs | 224 | 0.028404767943190464 | contain |
| n | ru | 223 | 0.02827796094344408 | contain |
| n | ren | 222 | 0.028151153943697688 | end |
| n | ag | 221 | 0.028024346943951305 | contain |
| n | au | 221 | 0.028024346943951305 | begin |
| n | hl | 218 | 0.02764392594471215 | contain |
| n | tu | 217 | 0.02751711894496576 | contain |
| n | pi | 216 | 0.027390311945219376 | contain |
| n | ach | 216 | 0.027390311945219376 | contain |
| n | ba | 214 | 0.0271366979457266 | contain |
| n | ut | 213 | 0.02700989094598022 | contain |
| n | ung | 212 | 0.02688308394623384 | contain |
| n | hi | 209 | 0.026502662946994673 | contain |
| n | ern | 209 | 0.026502662946994673 | contain |
| n | nde | 209 | 0.026502662946994673 | contain |
| n | rk | 205 | 0.02599543494800913 | contain |
| n | tz | 204 | 0.025868627948262744 | contain |
| n | di | 203 | 0.025741820948516358 | contain |
| n | pr | 200 | 0.0253613999492772 | contain |
| n | uc | 200 | 0.0253613999492772 | contain |
| n | ben | 199 | 0.02523459294953081 | contain |
| n | lt | 197 | 0.024980978950038042 | contain |
| n | nk | 197 | 0.024980978950038042 | contain |
| n | ve | 197 | 0.024980978950038042 | begin |
| n | uf | 195 | 0.02472736495054527 | contain |
| n | rb | 194 | 0.024600557950798883 | contain |
| n | im | 193 | 0.0244737509510525 | contain |
| n | pa | 192 | 0.02434694395130612 | contain |
| n | ah | 189 | 0.02396652295206696 | contain |
| n | eg | 189 | 0.02396652295206696 | contain |
| n | ver | 188 | 0.023839715952320567 | begin |
| n | lo | 185 | 0.02345929495308141 | contain |
| n | lu | 185 | 0.02345929495308141 | contain |
| n | om | 185 | 0.02345929495308141 | contain |
| n | sa | 185 | 0.02345929495308141 | contain |
| n | br | 184 | 0.023332487953335024 | contain |
| n | ungs | 184 | 0.023332487953335024 | contain |
| n | hau | 183 | 0.02320568095358864 | contain |
| n | zi | 182 | 0.02307887395384225 | contain |
| n | ad | 178 | 0.02257164595485671 | contain |
| n | ter | 176 | 0.022318031955363936 | end |
| n | rei | 176 | 0.022318031955363936 | contain |
| n | fl | 175 | 0.02219122495561755 | contain |
| n | bl | 174 | 0.022064417955871163 | contain |
| n | ld | 172 | 0.0218108039563784 | end |
| n | ers | 172 | 0.0218108039563784 | contain |
| n | tel | 172 | 0.0218108039563784 | contain |
| n | ken | 171 | 0.02168399695663201 | contain |
| n | uch | 170 | 0.02155718995688562 | contain |
| n | icht | 170 | 0.02155718995688562 | contain |
| n | in | 168 | 0.021303575957392847 | end |
| n | ed | 167 | 0.02117676895764646 | contain |
| n | ho | 166 | 0.02104996195790008 | contain |
| n | ges | 165 | 0.02092315495815369 | contain |
| n | ur | 162 | 0.02054273395891453 | contain |
| n | den | 162 | 0.02054273395891453 | contain |
| n | ing | 162 | 0.02054273395891453 | contain |
| n | ab | 161 | 0.020415926959168145 | begin |
| n | ten | 160 | 0.02028911995942176 | end |
| n | id | 159 | 0.020162312959675376 | contain |
| n | ul | 159 | 0.020162312959675376 | contain |
| n | lei | 159 | 0.020162312959675376 | contain |
| n | ht | 158 | 0.02003550595992899 | end |
| n | erk | 158 | 0.02003550595992899 | contain |
| n | cht | 157 | 0.019908698960182603 | end |
| n | wi | 157 | 0.019908698960182603 | contain |
| n | al | 156 | 0.019781891960436216 | end |
| n | gr | 153 | 0.019401470961197056 | contain |
| n | rg | 153 | 0.019401470961197056 | contain |
| n | ug | 153 | 0.019401470961197056 | contain |
| n | ig | 151 | 0.019147856961704287 | contain |
| n | kr | 149 | 0.018894242962211514 | contain |
| n | ster | 149 | 0.018894242962211514 | contain |
| n | sen | 148 | 0.018767435962465127 | end |
| n | be | 148 | 0.018767435962465127 | begin |
| n | ben | 146 | 0.018513821962972358 | end |
| n | ech | 146 | 0.018513821962972358 | contain |
| n | ha | 146 | 0.018513821962972358 | begin |
| n | gen | 145 | 0.018387014963225968 | end |
| n | ei | 145 | 0.018387014963225968 | begin |
| n | os | 144 | 0.018260207963479585 | contain |
| n | gel | 144 | 0.018260207963479585 | contain |
| n | zen | 144 | 0.018260207963479585 | contain |
| n | ue | 143 | 0.0181334009637332 | contain |
| n | sche | 143 | 0.0181334009637332 | contain |
| n | est | 142 | 0.018006593963986812 | contain |
| n | wer | 142 | 0.018006593963986812 | contain |
| n | rn | 141 | 0.017879786964240425 | end |
| n | ka | 141 | 0.017879786964240425 | begin |
| n | fi | 140 | 0.017752979964494042 | contain |
| n | iu | 140 | 0.017752979964494042 | contain |
| n | der | 140 | 0.017752979964494042 | contain |
| n | ens | 140 | 0.017752979964494042 | contain |
| n | ium | 139 | 0.017626172964747656 | contain |
| n | mo | 138 | 0.01749936596500127 | contain |
| n | auf | 138 | 0.01749936596500127 | contain |
| n | chl | 138 | 0.01749936596500127 | contain |
| n | bo | 137 | 0.017372558965254883 | contain |
| n | chi | 137 | 0.017372558965254883 | contain |
| n | nge | 137 | 0.017372558965254883 | contain |
| n | pie | 136 | 0.017245751965508496 | contain |
| n | pf | 135 | 0.01711894496576211 | contain |
| n | hn | 134 | 0.016992137966015727 | contain |
| n | ir | 134 | 0.016992137966015727 | contain |
| n | ser | 134 | 0.016992137966015727 | contain |
| n | us | 133 | 0.016865330966269337 | end |
| n | bu | 133 | 0.016865330966269337 | contain |
| n | kt | 133 | 0.016865330966269337 | contain |
| n | rd | 133 | 0.016865330966269337 | contain |
| n | eis | 133 | 0.016865330966269337 | contain |
| n | eri | 133 | 0.016865330966269337 | contain |
| n | erb | 132 | 0.016738523966522954 | contain |
| n | isc | 132 | 0.016738523966522954 | contain |
| n | len | 132 | 0.016738523966522954 | contain |
| n | nte | 132 | 0.016738523966522954 | contain |
| n | isch | 132 | 0.016738523966522954 | contain |
| n | kl | 130 | 0.01648490996703018 | contain |
| n | rm | 129 | 0.016358102967283794 | contain |
| n | age | 129 | 0.016358102967283794 | contain |
| n | nd | 128 | 0.01623129596753741 | end |
| n | cke | 128 | 0.01623129596753741 | contain |
| n | fen | 128 | 0.01623129596753741 | contain |
| n | haus | 127 | 0.016104488967791018 | contain |
| n | re | 127 | 0.016104488967791018 | begin |
| n | ium | 126 | 0.015977681968044638 | end |
| n | ef | 125 | 0.01585087496829825 | contain |
| n | eit | 125 | 0.01585087496829825 | contain |
| n | da | 123 | 0.015597260968805478 | contain |
| n | su | 123 | 0.015597260968805478 | contain |
| n | geb | 123 | 0.015597260968805478 | contain |
| n | sta | 123 | 0.015597260968805478 | contain |
| n | ew | 122 | 0.01547045396905909 | contain |
| n | hu | 122 | 0.01547045396905909 | contain |
| n | nz | 122 | 0.01547045396905909 | contain |
| n | hei | 121 | 0.015343646969312704 | contain |
| n | iel | 120 | 0.015216839969566319 | contain |
| n | et | 119 | 0.015090032969819934 | end |
| n | so | 119 | 0.015090032969819934 | contain |
| n | fer | 119 | 0.015090032969819934 | contain |
| n | her | 119 | 0.015090032969819934 | contain |
| n | mit | 119 | 0.015090032969819934 | contain |
| n | spi | 119 | 0.015090032969819934 | contain |
| n | schi | 119 | 0.015090032969819934 | contain |
| n | an | 119 | 0.015090032969819934 | begin |
| n | ki | 118 | 0.014963225970073548 | contain |
| n | hw | 117 | 0.014836418970327163 | contain |
| n | eld | 117 | 0.014836418970327163 | contain |
| n | lie | 117 | 0.014836418970327163 | contain |
| n | ko | 117 | 0.014836418970327163 | begin |
| n | ken | 116 | 0.014709611970580775 | end |
| n | oc | 116 | 0.014709611970580775 | contain |
| n | po | 116 | 0.014709611970580775 | contain |
| n | eic | 116 | 0.014709611970580775 | contain |
| n | rec | 116 | 0.014709611970580775 | contain |
| n | eich | 116 | 0.014709611970580775 | contain |
| n | em | 115 | 0.01458280497083439 | end |
| n | aus | 115 | 0.01458280497083439 | end |
| n | no | 115 | 0.01458280497083439 | contain |
| n | ger | 115 | 0.01458280497083439 | contain |
| n | mp | 114 | 0.014455997971088003 | contain |
| n | op | 114 | 0.014455997971088003 | contain |
| n | tra | 114 | 0.014455997971088003 | contain |
| n | schl | 114 | 0.014455997971088003 | contain |
| n | wa | 114 | 0.014455997971088003 | begin |
| n | haus | 113 | 0.014329190971341619 | end |
| n | ek | 113 | 0.014329190971341619 | contain |
| n | sy | 113 | 0.014329190971341619 | contain |
| n | ahr | 113 | 0.014329190971341619 | contain |
| n | chw | 113 | 0.014329190971341619 | contain |
| n | ind | 113 | 0.014329190971341619 | contain |
| n | gl | 112 | 0.014202383971595232 | contain |
| n | fe | 112 | 0.014202383971595232 | begin |
| n | if | 110 | 0.013948769972102459 | contain |
| n | tem | 110 | 0.013948769972102459 | contain |
| n | fo | 109 | 0.013821962972356074 | contain |
| n | cha | 109 | 0.013821962972356074 | contain |
| n | aus | 109 | 0.013821962972356074 | begin |
| n | ga | 108 | 0.013695155972609688 | contain |
| n | rau | 107 | 0.0135683489728633 | contain |
| n | he | 107 | 0.0135683489728633 | begin |
| n | sp | 107 | 0.0135683489728633 | begin |
| n | ein | 107 | 0.0135683489728633 | begin |
| n | af | 106 | 0.013441541973116916 | contain |
| n | end | 106 | 0.013441541973116916 | contain |
| n | pro | 106 | 0.013441541973116916 | contain |
| n | ap | 105 | 0.01331473497337053 | contain |
| n | hre | 105 | 0.01331473497337053 | contain |
| n | icht | 104 | 0.013187927973624143 | end |
| n | ft | 104 | 0.013187927973624143 | contain |
| n | ys | 104 | 0.013187927973624143 | contain |
| n | lan | 104 | 0.013187927973624143 | contain |
| n | ma | 104 | 0.013187927973624143 | begin |
| n | at | 103 | 0.013061120973877759 | end |
| n | ern | 103 | 0.013061120973877759 | end |
| n | men | 103 | 0.013061120973877759 | end |
| n | ik | 103 | 0.013061120973877759 | contain |
| n | rf | 103 | 0.013061120973877759 | contain |
| n | rz | 103 | 0.013061120973877759 | contain |
| n | iche | 103 | 0.013061120973877759 | contain |
| n | ba | 103 | 0.013061120973877759 | begin |
| n | ln | 102 | 0.012934313974131372 | contain |
| n | vo | 102 | 0.012934313974131372 | contain |
| n | eck | 102 | 0.012934313974131372 | contain |
| n | ert | 102 | 0.012934313974131372 | contain |
| n | ild | 102 | 0.012934313974131372 | contain |
| n | schw | 102 | 0.012934313974131372 | contain |
| n | alt | 101 | 0.012807506974384986 | contain |
| n | nter | 101 | 0.012807506974384986 | contain |
| n | sg | 100 | 0.0126806999746386 | contain |
| n | nb | 99 | 0.012553892974892214 | contain |
| n | eln | 99 | 0.012553892974892214 | contain |
| n | rie | 99 | 0.012553892974892214 | contain |
| n | ln | 98 | 0.012427085975145828 | end |
| n | on | 98 | 0.012427085975145828 | end |
| n | eld | 98 | 0.012427085975145828 | end |
| n | eln | 98 | 0.012427085975145828 | end |
| n | rech | 98 | 0.012427085975145828 | contain |
| n | oh | 97 | 0.012300278975399441 | contain |
| n | stem | 97 | 0.012300278975399441 | contain |
| n | ku | 96 | 0.012173471975653057 | contain |
| n | spie | 96 | 0.012173471975653057 | contain |
| n | hm | 95 | 0.01204666497590667 | contain |
| n | erg | 95 | 0.01204666497590667 | contain |
| n | gra | 95 | 0.01204666497590667 | contain |
| n | nis | 95 | 0.01204666497590667 | contain |
| n | yst | 95 | 0.01204666497590667 | contain |
| n | rh | 94 | 0.011919857976160284 | contain |
| n | dr | 93 | 0.0117930509764139 | contain |
| n | io | 93 | 0.0117930509764139 | contain |
| n | vi | 93 | 0.0117930509764139 | contain |
| n | yste | 93 | 0.0117930509764139 | contain |
| n | and | 92 | 0.011666243976667512 | end |
| n | den | 92 | 0.011666243976667512 | end |
| n | ier | 92 | 0.011666243976667512 | end |
| n | tel | 92 | 0.011666243976667512 | end |
| n | do | 92 | 0.011666243976667512 | contain |
| n | fr | 92 | 0.011666243976667512 | contain |
| n | ls | 92 | 0.011666243976667512 | contain |
| n | was | 92 | 0.011666243976667512 | contain |
| n | piel | 92 | 0.011666243976667512 | contain |
| n | fa | 92 | 0.011666243976667512 | begin |
| n | tem | 91 | 0.011539436976921126 | end |
| n | ib | 91 | 0.011539436976921126 | contain |
| n | sk | 91 | 0.011539436976921126 | contain |
| n | eil | 91 | 0.011539436976921126 | contain |
| n | werk | 91 | 0.011539436976921126 | contain |
| n | we | 91 | 0.011539436976921126 | begin |
| n | stem | 90 | 0.011412629977174741 | end |
| n | du | 90 | 0.011412629977174741 | contain |
| n | gi | 90 | 0.011412629977174741 | contain |
| n | mu | 90 | 0.011412629977174741 | contain |
| n | nf | 90 | 0.011412629977174741 | contain |
| n | bil | 90 | 0.011412629977174741 | contain |
| n | ram | 90 | 0.011412629977174741 | contain |
| n | sge | 90 | 0.011412629977174741 | contain |
| n | ot | 89 | 0.011285822977428354 | end |
| n | bs | 89 | 0.011285822977428354 | contain |
| n | th | 89 | 0.011285822977428354 | contain |
| n | str | 89 | 0.011285822977428354 | contain |
| n | tie | 89 | 0.011285822977428354 | contain |
| n | pa | 89 | 0.011285822977428354 | begin |
| n | auf | 89 | 0.011285822977428354 | begin |
| n | ob | 88 | 0.011159015977681968 | contain |
| n | rk | 87 | 0.01103220897793558 | end |
| n | ber | 87 | 0.01103220897793558 | contain |
| n | lte | 87 | 0.01103220897793558 | contain |
| n | scha | 87 | 0.01103220897793558 | contain |
| n | len | 86 | 0.010905401978189195 | end |
| n | uch | 86 | 0.010905401978189195 | end |
| n | nst | 86 | 0.010905401978189195 | contain |
| n | rge | 86 | 0.010905401978189195 | contain |
| n | tei | 86 | 0.010905401978189195 | contain |
| n | na | 86 | 0.010905401978189195 | begin |
| n | il | 85 | 0.01077859497844281 | end |
| n | fen | 85 | 0.01077859497844281 | end |
| n | las | 85 | 0.01077859497844281 | contain |
| n | se | 85 | 0.01077859497844281 | begin |
| n | iel | 84 | 0.010651787978696424 | end |
| n | ia | 84 | 0.010651787978696424 | contain |
| n | rl | 84 | 0.010651787978696424 | contain |
| n | und | 84 | 0.010651787978696424 | contain |
| n | erk | 83 | 0.01052498097895004 | end |
| n | ate | 83 | 0.01052498097895004 | contain |
| n | lag | 83 | 0.01052498097895004 | contain |
| n | mer | 83 | 0.01052498097895004 | contain |
| n | zei | 83 | 0.01052498097895004 | contain |
| n | le | 83 | 0.01052498097895004 | begin |
| n | chu | 82 | 0.010398173979203652 | contain |
| n | eid | 82 | 0.010398173979203652 | contain |
| n | rte | 82 | 0.010398173979203652 | contain |
| n | cken | 82 | 0.010398173979203652 | contain |
| n | tr | 82 | 0.010398173979203652 | begin |
| n | werk | 81 | 0.010271366979457266 | end |
| n | nh | 81 | 0.010271366979457266 | contain |
| n | up | 81 | 0.010271366979457266 | contain |
| n | gew | 81 | 0.010271366979457266 | contain |
| n | per | 81 | 0.010271366979457266 | contain |
| n | is | 80 | 0.01014455997971088 | end |
| n | ng | 80 | 0.01014455997971088 | end |
| n | ak | 80 | 0.01014455997971088 | contain |
| n | erf | 80 | 0.01014455997971088 | contain |
| n | etz | 80 | 0.01014455997971088 | contain |
| n | hal | 80 | 0.01014455997971088 | contain |
| n | wei | 80 | 0.01014455997971088 | contain |
| n | uer | 79 | 0.010017752979964495 | contain |
| n | la | 79 | 0.010017752979964495 | begin |
| n | me | 79 | 0.010017752979964495 | begin |
| m | er | 3703 | 0.3254240267158801 | contain |
| m | ch | 2800 | 0.2460673169874329 | contain |
| m | en | 2369 | 0.208190526408296 | contain |
| m | er | 1960 | 0.1722471218912031 | end |
| m | st | 1754 | 0.1541435978556991 | contain |
| m | sc | 1647 | 0.1447403110993936 | contain |
| m | te | 1633 | 0.14350997451445646 | contain |
| m | sch | 1628 | 0.1430705685912646 | contain |
| m | an | 1536 | 0.13498549960453468 | contain |
| m | ei | 1519 | 0.13349151946568238 | contain |
| m | el | 1208 | 0.10616047104314966 | contain |
| m | au | 1188 | 0.10440284735038227 | contain |
| m | ra | 1124 | 0.09877845153352667 | contain |
| m | re | 1093 | 0.09605413480973723 | contain |
| m | in | 1068 | 0.09385710519377803 | contain |
| m | ge | 1017 | 0.0893751647772212 | contain |
| m | be | 997 | 0.08761754108445381 | contain |
| m | ie | 947 | 0.08322348185253538 | contain |
| m | nd | 923 | 0.08111433342121452 | contain |
| m | us | 914 | 0.0803234027594692 | contain |
| m | la | 861 | 0.07566569997363565 | contain |
| m | un | 837 | 0.07355655154231479 | contain |
| m | le | 828 | 0.07276562088056948 | contain |
| m | he | 827 | 0.0726777396959311 | contain |
| m | al | 822 | 0.07223833377273926 | contain |
| m | en | 809 | 0.07109587837244045 | end |
| m | ns | 806 | 0.07083223481852535 | contain |
| m | ng | 803 | 0.07056859126461025 | contain |
| m | ta | 796 | 0.06995342297214166 | contain |
| m | is | 787 | 0.06916249231039634 | contain |
| m | de | 782 | 0.0687230863872045 | contain |
| m | ri | 768 | 0.06749274980226734 | contain |
| m | at | 766 | 0.0673169874329906 | contain |
| m | or | 755 | 0.06635029440196852 | contain |
| m | tr | 749 | 0.06582300729413833 | contain |
| m | ter | 736 | 0.06468055189383952 | contain |
| m | ha | 702 | 0.06169259161613499 | contain |
| m | it | 702 | 0.06169259161613499 | contain |
| m | ar | 701 | 0.06160471043149661 | contain |
| m | se | 700 | 0.06151682924685824 | contain |
| m | es | 647 | 0.05685912646102469 | contain |
| m | fe | 644 | 0.056595482907109584 | contain |
| m | nt | 626 | 0.05501362158361895 | contain |
| m | ke | 553 | 0.04859829510501802 | contain |
| m | sc | 551 | 0.048422532735741285 | begin |
| m | ne | 548 | 0.04815888918182617 | contain |
| m | sch | 544 | 0.04780736444327269 | begin |
| m | ck | 543 | 0.04771948325863433 | contain |
| m | el | 537 | 0.04719219615080411 | end |
| m | sa | 533 | 0.04684067141225064 | contain |
| m | me | 521 | 0.04578609719659021 | contain |
| m | ru | 516 | 0.04534669127339837 | contain |
| m | on | 510 | 0.04481940416556815 | contain |
| m | ic | 509 | 0.044731522980929785 | contain |
| m | rt | 507 | 0.04455576061165305 | contain |
| m | rs | 505 | 0.04437999824237631 | contain |
| m | ag | 504 | 0.04429211705773794 | contain |
| m | hl | 501 | 0.04402847350382283 | contain |
| m | ma | 501 | 0.04402847350382283 | contain |
| m | ch | 500 | 0.043940592319184464 | end |
| m | tz | 496 | 0.04358906758063099 | contain |
| m | che | 495 | 0.04350118639599262 | contain |
| m | ts | 476 | 0.041831443887863605 | contain |
| m | we | 475 | 0.04174356270322524 | contain |
| m | sp | 474 | 0.04165568151858687 | contain |
| m | to | 474 | 0.04165568151858687 | contain |
| m | as | 467 | 0.041040513226118285 | contain |
| m | ro | 462 | 0.04060110730292645 | contain |
| m | li | 460 | 0.04042534493364972 | contain |
| m | nk | 455 | 0.03998593901045786 | contain |
| m | ka | 454 | 0.03989805782581949 | contain |
| m | ti | 452 | 0.03972229545654275 | contain |
| m | ens | 451 | 0.03963441427190439 | contain |
| m | ve | 440 | 0.03866772124088233 | contain |
| m | uc | 435 | 0.038228315317690484 | contain |
| m | ter | 422 | 0.03708585991739169 | end |
| m | ba | 420 | 0.03691009754811495 | contain |
| m | sta | 418 | 0.03673433517883822 | contain |
| m | rei | 416 | 0.03655857280956147 | contain |
| m | ich | 411 | 0.03611916688636963 | contain |
| m | ste | 408 | 0.035855523332454516 | contain |
| m | na | 407 | 0.03576764214781615 | contain |
| m | and | 403 | 0.03541611740926268 | contain |
| m | ko | 401 | 0.03524035503998594 | contain |
| m | ur | 398 | 0.03497671148607083 | contain |
| m | uf | 397 | 0.034888830301432465 | contain |
| m | wa | 393 | 0.03453730556287899 | contain |
| m | um | 387 | 0.034010018455048766 | contain |
| m | lu | 386 | 0.033922137270410414 | contain |
| m | ht | 385 | 0.033834256085772035 | contain |
| m | ver | 385 | 0.033834256085772035 | contain |
| m | ac | 384 | 0.03374637490113367 | contain |
| m | ze | 381 | 0.03348273134721856 | contain |
| m | am | 379 | 0.033306968977941824 | contain |
| m | et | 376 | 0.03304332542402672 | contain |
| m | st | 369 | 0.03242815713155813 | begin |
| m | ol | 368 | 0.032340275946919766 | contain |
| m | ut | 366 | 0.03216451357764303 | contain |
| m | cht | 364 | 0.03198875120836628 | contain |
| m | gs | 363 | 0.03190087002372792 | contain |
| m | eg | 356 | 0.03128570173125934 | contain |
| m | pf | 354 | 0.0311099393619826 | contain |
| m | il | 353 | 0.03102205817734423 | contain |
| m | kt | 344 | 0.03023112751559891 | contain |
| m | ung | 343 | 0.030143246330960542 | contain |
| m | pe | 341 | 0.029967483961683805 | contain |
| m | ein | 335 | 0.029440196853853587 | contain |
| m | fa | 334 | 0.029352315669215225 | contain |
| m | us | 328 | 0.028825028561385007 | end |
| m | hu | 326 | 0.02864926619210827 | contain |
| m | ab | 323 | 0.028385622638193164 | contain |
| m | gen | 322 | 0.028297741453554792 | contain |
| m | ec | 321 | 0.028209860268916424 | contain |
| m | uch | 320 | 0.02812197908427805 | contain |
| m | her | 319 | 0.028034097899639687 | contain |
| m | hr | 318 | 0.027946216715001318 | contain |
| m | pr | 315 | 0.02768257316108621 | contain |
| m | eb | 314 | 0.027594691976447844 | contain |
| m | eh | 314 | 0.027594691976447844 | contain |
| m | mu | 314 | 0.027594691976447844 | contain |
| m | ten | 314 | 0.027594691976447844 | contain |
| m | ber | 303 | 0.026627998945425783 | contain |
| m | br | 297 | 0.026100711837595568 | contain |
| m | si | 297 | 0.026100711837595568 | contain |
| m | ers | 296 | 0.026012830652957203 | contain |
| m | ngs | 296 | 0.026012830652957203 | contain |
| m | chl | 295 | 0.02592494946831884 | contain |
| m | rb | 292 | 0.025661305914403725 | contain |
| m | rk | 287 | 0.025221899991211882 | contain |
| m | di | 283 | 0.024870375252658405 | contain |
| m | tz | 282 | 0.02478249406802004 | end |
| m | nde | 282 | 0.02478249406802004 | contain |
| m | schl | 281 | 0.024694612883381668 | contain |
| m | hn | 280 | 0.0246067316987433 | contain |
| m | eit | 280 | 0.0246067316987433 | contain |
| m | tu | 276 | 0.024255206960189825 | contain |
| m | ng | 275 | 0.024167325775551453 | end |
| m | nd | 273 | 0.02399156340627472 | end |
| m | ah | 273 | 0.02399156340627472 | contain |
| m | str | 273 | 0.02399156340627472 | contain |
| m | eu | 272 | 0.023903682221636347 | contain |
| m | eis | 272 | 0.023903682221636347 | contain |
| m | tra | 272 | 0.023903682221636347 | contain |
| m | der | 269 | 0.02364003866772124 | contain |
| m | ug | 267 | 0.023464276298444504 | contain |
| m | ck | 265 | 0.023288513929167764 | end |
| m | auf | 265 | 0.023288513929167764 | contain |
| m | mi | 263 | 0.023112751559891027 | contain |
| m | ge | 263 | 0.023112751559891027 | begin |
| m | ler | 262 | 0.023024870375252655 | contain |
| m | ni | 258 | 0.022673345636699184 | contain |
| m | kr | 257 | 0.02258546445206081 | contain |
| m | aus | 257 | 0.02258546445206081 | contain |
| m | pa | 255 | 0.022409702082784075 | contain |
| m | ang | 254 | 0.022321820898145703 | contain |
| m | ho | 250 | 0.021970296159592232 | contain |
| m | ungs | 249 | 0.021882414974953864 | contain |
| m | st | 247 | 0.021706652605677126 | end |
| m | ach | 247 | 0.021706652605677126 | contain |
| m | ad | 245 | 0.021530890236400386 | contain |
| m | ot | 245 | 0.021530890236400386 | contain |
| m | wi | 245 | 0.021530890236400386 | contain |
| m | nst | 244 | 0.021443009051762017 | contain |
| m | hi | 241 | 0.021179365497846908 | contain |
| m | fl | 240 | 0.021091484313208543 | contain |
| m | lt | 237 | 0.02082784075929344 | contain |
| m | sm | 237 | 0.02082784075929344 | contain |
| m | cha | 236 | 0.020739959574655062 | contain |
| m | ler | 235 | 0.020652078390016697 | end |
| m | zu | 234 | 0.020564197205378328 | contain |
| m | rie | 234 | 0.020564197205378328 | contain |
| m | rm | 233 | 0.02047631602073996 | contain |
| m | mp | 232 | 0.02038843483610159 | contain |
| m | ga | 230 | 0.020212672466824854 | contain |
| m | ent | 230 | 0.020212672466824854 | contain |
| m | rau | 228 | 0.02003691009754812 | contain |
| m | be | 227 | 0.019949028912909745 | begin |
| m | chu | 226 | 0.019861147728271376 | contain |
| m | if | 225 | 0.019773266543633008 | contain |
| m | ku | 225 | 0.019773266543633008 | contain |
| m | ha | 225 | 0.019773266543633008 | begin |
| m | nte | 223 | 0.019597504174356267 | contain |
| m | bo | 222 | 0.019509622989717902 | contain |
| m | ef | 222 | 0.019509622989717902 | contain |
| m | fi | 219 | 0.0192459794358028 | contain |
| m | ag | 217 | 0.019070217066526056 | end |
| m | po | 217 | 0.019070217066526056 | contain |
| m | ier | 217 | 0.019070217066526056 | contain |
| m | tan | 216 | 0.018982335881887687 | contain |
| m | schu | 214 | 0.01880657351261095 | contain |
| m | ger | 212 | 0.018630811143334213 | contain |
| m | mus | 212 | 0.018630811143334213 | contain |
| m | ka | 211 | 0.018542929958695845 | begin |
| m | da | 209 | 0.018367167589419104 | contain |
| m | den | 208 | 0.01827928640478073 | contain |
| m | ran | 208 | 0.01827928640478073 | contain |
| m | op | 207 | 0.01819140522014237 | contain |
| m | cher | 207 | 0.01819140522014237 | contain |
| m | nz | 206 | 0.018103524035504 | contain |
| m | om | 206 | 0.018103524035504 | contain |
| m | gr | 202 | 0.017751999296950524 | contain |
| m | ir | 201 | 0.017664118112312156 | contain |
| m | ko | 201 | 0.017664118112312156 | begin |
| m | af | 199 | 0.017488355743035415 | contain |
| m | scha | 199 | 0.017488355743035415 | contain |
| m | sche | 199 | 0.017488355743035415 | contain |
| m | ner | 198 | 0.017400474558397046 | contain |
| m | rn | 196 | 0.01722471218912031 | contain |
| m | au | 195 | 0.01713683100448194 | begin |
| m | dr | 194 | 0.017048949819843572 | contain |
| m | rd | 193 | 0.016961068635205204 | contain |
| m | ech | 193 | 0.016961068635205204 | contain |
| m | oc | 192 | 0.016873187450566842 | contain |
| m | nsc | 192 | 0.016873187450566842 | contain |
| m | pu | 191 | 0.016785306265928463 | contain |
| m | or | 190 | 0.016697425081290098 | end |
| m | ak | 190 | 0.016697425081290098 | contain |
| m | nsch | 190 | 0.016697425081290098 | contain |
| m | os | 188 | 0.016521662712013357 | contain |
| m | atz | 188 | 0.016521662712013357 | contain |
| m | ker | 188 | 0.016521662712013357 | contain |
| m | ft | 187 | 0.01643378152737499 | contain |
| m | age | 187 | 0.01643378152737499 | contain |
| m | sp | 187 | 0.01643378152737499 | begin |
| m | ld | 186 | 0.01634590034273662 | contain |
| m | lo | 186 | 0.01634590034273662 | contain |
| m | pi | 186 | 0.01634590034273662 | contain |
| m | ve | 186 | 0.01634590034273662 | begin |
| m | vo | 185 | 0.016258019158098252 | contain |
| m | fr | 184 | 0.016170137973459883 | contain |
| m | aum | 184 | 0.016170137973459883 | contain |
| m | sch | 183 | 0.016082256788821515 | end |
| m | ls | 183 | 0.016082256788821515 | contain |
| m | ap | 182 | 0.015994375604183143 | contain |
| m | ed | 182 | 0.015994375604183143 | contain |
| m | mus | 181 | 0.015906494419544774 | end |
| m | mo | 181 | 0.015906494419544774 | contain |
| m | kt | 180 | 0.015818613234906406 | end |
| m | pl | 180 | 0.015818613234906406 | contain |
| m | tel | 180 | 0.015818613234906406 | contain |
| m | wa | 180 | 0.015818613234906406 | begin |
| m | zi | 179 | 0.015730732050268037 | contain |
| m | fer | 179 | 0.015730732050268037 | contain |
| m | re | 179 | 0.015730732050268037 | begin |
| m | hs | 178 | 0.01564285086562967 | contain |
| m | so | 178 | 0.01564285086562967 | contain |
| m | ser | 178 | 0.01564285086562967 | contain |
| m | tor | 178 | 0.01564285086562967 | contain |
| m | icht | 178 | 0.01564285086562967 | contain |
| m | nb | 177 | 0.0155549696809913 | contain |
| m | ba | 176 | 0.015467088496352931 | begin |
| m | ver | 176 | 0.015467088496352931 | begin |
| m | ing | 175 | 0.01537920731171456 | contain |
| m | sen | 174 | 0.01529132612707619 | contain |
| m | hm | 172 | 0.015115563757799455 | contain |
| m | im | 172 | 0.015115563757799455 | contain |
| m | und | 172 | 0.015115563757799455 | contain |
| m | ert | 171 | 0.015027682573161087 | contain |
| m | smu | 171 | 0.015027682573161087 | contain |
| m | her | 169 | 0.014851920203884346 | end |
| m | sb | 167 | 0.014676157834607613 | contain |
| m | lei | 167 | 0.014676157834607613 | contain |
| m | rsc | 167 | 0.014676157834607613 | contain |
| m | ruc | 167 | 0.014676157834607613 | contain |
| m | rsch | 167 | 0.014676157834607613 | contain |
| m | and | 166 | 0.01458827664996924 | end |
| m | rg | 165 | 0.014500395465330872 | contain |
| m | hei | 165 | 0.014500395465330872 | contain |
| m | lau | 165 | 0.014500395465330872 | contain |
| m | bu | 164 | 0.014412514280692503 | contain |
| m | ig | 164 | 0.014412514280692503 | contain |
| m | hen | 164 | 0.014412514280692503 | contain |
| m | man | 164 | 0.014412514280692503 | contain |
| m | uch | 163 | 0.014324633096054137 | end |
| m | ul | 163 | 0.014324633096054137 | contain |
| m | enst | 163 | 0.014324633096054137 | contain |
| m | chs | 162 | 0.014236751911415766 | contain |
| m | ien | 162 | 0.014236751911415766 | contain |
| m | ist | 162 | 0.014236751911415766 | contain |
| m | kl | 161 | 0.014148870726777396 | contain |
| m | of | 161 | 0.014148870726777396 | contain |
| m | bau | 161 | 0.014148870726777396 | contain |
| m | ism | 161 | 0.014148870726777396 | contain |
| m | um | 160 | 0.014060989542139028 | end |
| m | est | 160 | 0.014060989542139028 | contain |
| m | gel | 160 | 0.014060989542139028 | contain |
| m | ismu | 160 | 0.014060989542139028 | contain |
| m | ort | 159 | 0.013973108357500659 | contain |
| m | ma | 159 | 0.013973108357500659 | begin |
| m | no | 158 | 0.01388522717286229 | contain |
| m | erk | 158 | 0.01388522717286229 | contain |
| m | tri | 158 | 0.01388522717286229 | contain |
| m | in | 157 | 0.013797345988223922 | end |
| m | ik | 157 | 0.013797345988223922 | contain |
| m | ang | 156 | 0.013709464803585552 | end |
| m | erb | 156 | 0.013709464803585552 | contain |
| m | fen | 156 | 0.013709464803585552 | contain |
| m | ei | 156 | 0.013709464803585552 | begin |
| m | ug | 155 | 0.013621583618947185 | end |
| m | hla | 155 | 0.013621583618947185 | contain |
| m | tei | 155 | 0.013621583618947185 | contain |
| m | we | 155 | 0.013621583618947185 | begin |
| m | sk | 154 | 0.013533702434308814 | contain |
| m | chla | 154 | 0.013533702434308814 | contain |
| m | rt | 153 | 0.013445821249670446 | end |
| m | bl | 153 | 0.013445821249670446 | contain |
| m | ub | 153 | 0.013445821249670446 | contain |
| m | lan | 152 | 0.013357940065032077 | contain |
| m | tre | 152 | 0.013357940065032077 | contain |
| m | end | 150 | 0.01318217769575534 | contain |
| m | hau | 150 | 0.01318217769575534 | contain |
| m | atz | 148 | 0.0130064153264786 | end |
| m | cke | 148 | 0.0130064153264786 | contain |
| m | tr | 148 | 0.0130064153264786 | begin |
| m | aum | 147 | 0.012918534141840231 | end |
| m | bs | 147 | 0.012918534141840231 | contain |
| m | rl | 147 | 0.012918534141840231 | contain |
| m | su | 147 | 0.012918534141840231 | contain |
| m | ue | 147 | 0.012918534141840231 | contain |
| m | alt | 147 | 0.012918534141840231 | contain |
| m | stan | 147 | 0.012918534141840231 | contain |
| m | pf | 146 | 0.012830652957201864 | end |
| m | rat | 146 | 0.012830652957201864 | contain |
| m | ek | 145 | 0.012742771772563494 | contain |
| m | nge | 145 | 0.012742771772563494 | contain |
| m | ger | 144 | 0.012654890587925124 | end |
| m | eic | 144 | 0.012654890587925124 | contain |
| m | hal | 144 | 0.012654890587925124 | contain |
| m | rbe | 144 | 0.012654890587925124 | contain |
| m | eich | 144 | 0.012654890587925124 | contain |
| m | ant | 143 | 0.012567009403286757 | contain |
| m | ind | 143 | 0.012567009403286757 | contain |
| m | lat | 143 | 0.012567009403286757 | contain |
| m | chen | 143 | 0.012567009403286757 | contain |
| m | ds | 142 | 0.012479128218648387 | contain |
| m | oh | 142 | 0.012479128218648387 | contain |
| m | run | 141 | 0.012391247034010018 | contain |
| m | nter | 141 | 0.012391247034010018 | contain |
| m | nf | 140 | 0.01230336584937165 | contain |
| m | od | 140 | 0.01230336584937165 | contain |
| m | ben | 140 | 0.01230336584937165 | contain |
| m | pla | 140 | 0.01230336584937165 | contain |
| m | ker | 139 | 0.01221548466473328 | end |
| m | ten | 139 | 0.01221548466473328 | end |
| m | tor | 138 | 0.012127603480094912 | end |
| m | ric | 137 | 0.012039722295456542 | contain |
| m | cher | 136 | 0.011951841110818174 | end |
| m | an | 136 | 0.011951841110818174 | begin |
| m | fe | 136 | 0.011951841110818174 | begin |
| m | ra | 136 | 0.011951841110818174 | begin |
| m | se | 136 | 0.011951841110818174 | begin |
| m | isc | 135 | 0.011863959926179805 | contain |
| m | ster | 135 | 0.011863959926179805 | contain |
| m | gen | 134 | 0.011776078741541436 | end |
| m | hw | 134 | 0.011776078741541436 | contain |
| m | lus | 134 | 0.011776078741541436 | contain |
| m | at | 133 | 0.011688197556903066 | end |
| m | chn | 133 | 0.011688197556903066 | contain |
| m | unk | 133 | 0.011688197556903066 | contain |
| m | la | 133 | 0.011688197556903066 | begin |
| m | art | 132 | 0.011600316372264698 | contain |
| m | ite | 132 | 0.011600316372264698 | contain |
| m | isch | 132 | 0.011600316372264698 | contain |
| m | nder | 132 | 0.011600316372264698 | contain |
| m | tand | 132 | 0.011600316372264698 | contain |
| m | ner | 131 | 0.011512435187626327 | end |
| m | bi | 131 | 0.011512435187626327 | contain |
| m | rz | 131 | 0.011512435187626327 | contain |
| m | kel | 131 | 0.011512435187626327 | contain |
| m | le | 131 | 0.011512435187626327 | begin |
| m | an | 130 | 0.011424554002987959 | end |
| m | ern | 130 | 0.011424554002987959 | contain |
| m | chi | 129 | 0.011336672818349592 | contain |
| m | ren | 129 | 0.011336672818349592 | contain |
| m | he | 129 | 0.011336672818349592 | begin |
| m | ack | 128 | 0.011248791633711222 | contain |
| m | chw | 128 | 0.011248791633711222 | contain |
| m | era | 128 | 0.011248791633711222 | contain |
| m | pa | 127 | 0.011160910449072851 | begin |
| m | io | 126 | 0.011073029264434485 | contain |
| m | ast | 126 | 0.011073029264434485 | contain |
| m | men | 126 | 0.011073029264434485 | contain |
| m | mer | 126 | 0.011073029264434485 | contain |
| m | wer | 126 | 0.011073029264434485 | contain |
| m | der | 125 | 0.010985148079796116 | end |
| m | lk | 125 | 0.010985148079796116 | contain |
| m | up | 125 | 0.010985148079796116 | contain |
| m | lag | 125 | 0.010985148079796116 | contain |
| m | wei | 125 | 0.010985148079796116 | contain |
| m | ensc | 125 | 0.010985148079796116 | contain |
| m | die | 124 | 0.01089726689515775 | contain |
| m | zug | 124 | 0.01089726689515775 | contain |
| m | ta | 124 | 0.01089726689515775 | begin |
| m | enk | 123 | 0.010809385710519377 | contain |
| m | spr | 123 | 0.010809385710519377 | contain |
| m | rich | 123 | 0.010809385710519377 | contain |
| m | chr | 122 | 0.010721504525881009 | contain |
| m | sel | 122 | 0.010721504525881009 | contain |
| m | sa | 122 | 0.010721504525881009 | begin |
| m | em | 121 | 0.01063362334124264 | contain |
| m | rf | 121 | 0.01063362334124264 | contain |
| m | eck | 121 | 0.01063362334124264 | contain |
| m | nke | 121 | 0.01063362334124264 | contain |
| m | vo | 121 | 0.01063362334124264 | begin |
| m | ich | 120 | 0.010545742156604272 | end |
| m | ki | 120 | 0.010545742156604272 | contain |
| m | han | 120 | 0.010545742156604272 | contain |
| m | id | 119 | 0.0104578609719659 | contain |
| m | ate | 119 | 0.0104578609719659 | contain |
| m | sta | 119 | 0.0104578609719659 | begin |
| m | fal | 118 | 0.010369979787327531 | contain |
| m | tro | 118 | 0.010369979787327531 | contain |
| m | fs | 117 | 0.010282098602689164 | contain |
| m | bes | 117 | 0.010282098602689164 | contain |
| m | sat | 117 | 0.010282098602689164 | contain |
| m | sti | 117 | 0.010282098602689164 | contain |
| m | ab | 117 | 0.010282098602689164 | begin |
| m | kr | 117 | 0.010282098602689164 | begin |
| m | ieg | 116 | 0.010194217418050796 | contain |
| m | itz | 116 | 0.010194217418050796 | contain |
| m | tsc | 116 | 0.010194217418050796 | contain |
| m | utz | 116 | 0.010194217418050796 | contain |
| m | tsch | 116 | 0.010194217418050796 | contain |
| m | ho | 116 | 0.010194217418050796 | begin |
| m | nt | 115 | 0.010106336233412429 | end |
| m | enb | 115 | 0.010106336233412429 | contain |
| m | uck | 115 | 0.010106336233412429 | contain |
| m | schw | 115 | 0.010106336233412429 | contain |
| m | do | 114 | 0.010018455048774057 | contain |
| m | du | 114 | 0.010018455048774057 | contain |
| m | opf | 114 | 0.010018455048774057 | contain |
| m | rst | 114 | 0.010018455048774057 | contain |
| m | ust | 114 | 0.010018455048774057 | contain |
| f | er | 4021 | 0.27987749704183196 | contain |
| f | un | 3416 | 0.2377671051715737 | contain |
| f | ch | 3371 | 0.2346349272638686 | contain |
| f | ng | 3203 | 0.22294146307510265 | contain |
| f | en | 3178 | 0.22120136423748868 | contain |
| f | ei | 2988 | 0.20797661307162246 | contain |
| f | ung | 2848 | 0.1982320595809842 | contain |
| f | te | 2605 | 0.18131829887937634 | contain |
| f | ng | 2380 | 0.16565740934085055 | end |
| f | ung | 2374 | 0.1652397856198232 | end |
| f | in | 2148 | 0.14950929212779285 | contain |
| f | st | 2097 | 0.14595949049906035 | contain |
| f | it | 1949 | 0.1356581053803856 | contain |
| f | sc | 1815 | 0.1263311756107747 | contain |
| f | sch | 1807 | 0.1257743439827382 | contain |
| f | re | 1772 | 0.12333820561007865 | contain |
| f | ge | 1756 | 0.1222245423540057 | contain |
| f | ie | 1720 | 0.11971880002784158 | contain |
| f | le | 1620 | 0.11275840467738568 | contain |
| f | an | 1590 | 0.11067028607224892 | contain |
| f | he | 1514 | 0.10538038560590242 | contain |
| f | be | 1490 | 0.103709890721793 | contain |
| f | el | 1471 | 0.10238741560520638 | contain |
| f | se | 1467 | 0.10210899979118812 | contain |
| f | eit | 1443 | 0.10043850490707873 | contain |
| f | ti | 1421 | 0.09890721792997842 | contain |
| f | ri | 1350 | 0.09396533723115473 | contain |
| f | ra | 1331 | 0.09264286211456813 | contain |
| f | on | 1261 | 0.08777058536924898 | contain |
| f | de | 1244 | 0.08658731815967148 | contain |
| f | au | 1147 | 0.07983573466972924 | contain |
| f | nd | 1125 | 0.07830444769262894 | contain |
| f | at | 1101 | 0.07663395280851952 | contain |
| f | ar | 1100 | 0.07656434885501498 | contain |
| f | la | 1073 | 0.07468504211039187 | contain |
| f | ke | 1055 | 0.0734321709473098 | contain |
| f | ne | 1049 | 0.07301454722628245 | contain |
| f | ha | 1036 | 0.07210969583072319 | contain |
| f | es | 1026 | 0.0714136562956776 | contain |
| f | is | 1016 | 0.070717616760632 | contain |
| f | en | 1005 | 0.06995197327208186 | end |
| f | li | 926 | 0.06445326094522169 | contain |
| f | it | 919 | 0.06396603327068978 | end |
| f | eit | 917 | 0.06382682536368066 | end |
| f | ns | 914 | 0.06361801350316698 | contain |
| f | ru | 898 | 0.06250435024709404 | contain |
| f | ta | 869 | 0.06048583559546183 | contain |
| f | al | 863 | 0.06006821187443447 | contain |
| f | me | 861 | 0.05992900396742535 | contain |
| f | io | 838 | 0.058328113036820485 | contain |
| f | tu | 829 | 0.05770167745527946 | contain |
| f | te | 821 | 0.05714484582724299 | end |
| f | or | 811 | 0.0564488062921974 | contain |
| f | nt | 795 | 0.05533514303612445 | contain |
| f | ve | 790 | 0.05498712326860165 | contain |
| f | in | 787 | 0.054778311408087976 | end |
| f | tr | 750 | 0.052202965128419286 | contain |
| f | ion | 750 | 0.052202965128419286 | contain |
| f | ic | 743 | 0.051715737453887384 | contain |
| f | si | 734 | 0.05108930187234635 | contain |
| f | rt | 716 | 0.04983643070926429 | contain |
| f | ht | 713 | 0.04962761884875061 | contain |
| f | ze | 707 | 0.049209995127723255 | contain |
| f | as | 704 | 0.04900118326720959 | contain |
| f | cht | 699 | 0.048653163499686784 | contain |
| f | lu | 692 | 0.04816593582515487 | contain |
| f | che | 692 | 0.04816593582515487 | contain |
| f | fe | 688 | 0.04788752001113663 | contain |
| f | ich | 679 | 0.0472610844295956 | contain |
| f | ver | 671 | 0.046704252801559126 | contain |
| f | ste | 669 | 0.04656504489455001 | contain |
| f | na | 668 | 0.04649544094104545 | contain |
| f | us | 668 | 0.04649544094104545 | contain |
| f | ts | 663 | 0.046147421173522656 | contain |
| f | rs | 654 | 0.045520985591981616 | contain |
| f | on | 632 | 0.04398969861488133 | end |
| f | ma | 628 | 0.04371128280086309 | contain |
| f | hr | 627 | 0.04364167884735853 | contain |
| f | ter | 624 | 0.04343286698684485 | contain |
| f | tio | 617 | 0.04294563931231294 | contain |
| f | ig | 616 | 0.04287603535880838 | contain |
| f | il | 616 | 0.04287603535880838 | contain |
| f | tion | 614 | 0.04273682745179926 | contain |
| f | ro | 612 | 0.04259761954479015 | contain |
| f | ion | 603 | 0.04197118396324912 | end |
| f | run | 592 | 0.04120554047469896 | contain |
| f | we | 586 | 0.04078791675367161 | contain |
| f | ka | 584 | 0.04064870884666249 | contain |
| f | ah | 573 | 0.03988306535811234 | contain |
| f | pe | 572 | 0.03981346140460778 | contain |
| f | eri | 568 | 0.03953504559058955 | contain |
| f | rin | 561 | 0.03904781791605763 | contain |
| f | sa | 558 | 0.03883900605554395 | contain |
| f | et | 555 | 0.03863019419503028 | contain |
| f | ol | 554 | 0.03856059024152572 | contain |
| f | se | 552 | 0.0384213823345166 | end |
| f | hei | 551 | 0.03835177838101205 | contain |
| f | ie | 547 | 0.038073362566993806 | end |
| f | sc | 546 | 0.03800375861348925 | begin |
| f | ft | 545 | 0.03793415465998469 | contain |
| f | sp | 544 | 0.03786455070648013 | contain |
| f | sch | 544 | 0.03786455070648013 | begin |
| f | af | 538 | 0.037446926985452766 | contain |
| f | ni | 526 | 0.036611679543398064 | contain |
| f | ag | 524 | 0.03647247163638895 | contain |
| f | le | 516 | 0.035915640008352484 | end |
| f | tun | 516 | 0.035915640008352484 | contain |
| f | ur | 510 | 0.035498016287325115 | contain |
| f | rung | 510 | 0.035498016287325115 | contain |
| f | ac | 509 | 0.03542841233382056 | contain |
| f | ten | 509 | 0.03542841233382056 | contain |
| f | rei | 508 | 0.035358808380316 | contain |
| f | tion | 507 | 0.035289204426811445 | end |
| f | gs | 505 | 0.03514999651980232 | contain |
| f | ko | 501 | 0.03487158070578409 | contain |
| f | wa | 483 | 0.033618709542702026 | contain |
| f | rin | 476 | 0.03313148186817011 | end |
| f | gen | 466 | 0.032435442333124516 | contain |
| f | eh | 464 | 0.0322962344261154 | contain |
| f | cha | 464 | 0.0322962344261154 | contain |
| f | eru | 464 | 0.0322962344261154 | contain |
| f | ab | 463 | 0.032226630472610845 | contain |
| f | tung | 462 | 0.032157026519106284 | contain |
| f | kei | 461 | 0.03208742256560173 | contain |
| f | nde | 460 | 0.03201781861209717 | contain |
| f | os | 459 | 0.031948214658592614 | contain |
| f | am | 454 | 0.03160019489106981 | contain |
| f | keit | 453 | 0.03153059093756525 | contain |
| f | ba | 452 | 0.0314609869840607 | contain |
| f | hi | 451 | 0.031391383030556136 | contain |
| f | ati | 446 | 0.03104336326303334 | contain |
| f | ier | 446 | 0.03104336326303334 | contain |
| f | rung | 442 | 0.030764947449015107 | end |
| f | hl | 442 | 0.030764947449015107 | contain |
| f | be | 441 | 0.030695343495510542 | begin |
| f | erin | 440 | 0.03062573954200598 | contain |
| f | mi | 439 | 0.030556135588501426 | contain |
| f | ers | 437 | 0.030416927681492317 | contain |
| f | ein | 436 | 0.03034732372798775 | contain |
| f | rb | 435 | 0.030277719774483187 | contain |
| f | di | 434 | 0.030208115820978636 | contain |
| f | erun | 434 | 0.030208115820978636 | contain |
| f | ge | 431 | 0.029999303960464963 | end |
| f | eg | 430 | 0.029929700006960394 | contain |
| f | ik | 426 | 0.029651284192942162 | contain |
| f | erin | 425 | 0.0295816802394376 | end |
| f | ve | 425 | 0.0295816802394376 | begin |
| f | scha | 424 | 0.029512076285933036 | contain |
| f | ut | 421 | 0.029303264425419362 | contain |
| f | ach | 421 | 0.029303264425419362 | contain |
| f | nk | 420 | 0.029233660471914807 | contain |
| f | ge | 420 | 0.029233660471914807 | begin |
| f | fa | 417 | 0.029024848611401127 | contain |
| f | ens | 416 | 0.02895524465789657 | contain |
| f | nz | 414 | 0.02881603675088745 | contain |
| f | hu | 413 | 0.028746432797382888 | contain |
| f | keit | 412 | 0.02867682884387833 | end |
| f | ver | 407 | 0.028328809076355536 | begin |
| f | pr | 406 | 0.028259205122850982 | contain |
| f | eu | 404 | 0.02811999721584186 | contain |
| f | st | 404 | 0.02811999721584186 | begin |
| f | lun | 399 | 0.027771977448319062 | contain |
| f | ne | 397 | 0.027632769541309943 | end |
| f | heit | 393 | 0.02735435372729171 | contain |
| f | lung | 388 | 0.027006333959768914 | contain |
| f | to | 387 | 0.02693673000626436 | contain |
| f | ngs | 387 | 0.02693673000626436 | contain |
| f | sta | 387 | 0.02693673000626436 | contain |
| f | de | 386 | 0.0268671260527598 | end |
| f | tung | 384 | 0.026727918145750682 | end |
| f | and | 381 | 0.026519106285237005 | contain |
| f | lo | 379 | 0.026379898378227882 | contain |
| f | ec | 377 | 0.02624069047121877 | contain |
| f | tz | 377 | 0.02624069047121877 | contain |
| f | atio | 377 | 0.02624069047121877 | contain |
| f | ck | 373 | 0.02596227465720053 | contain |
| f | du | 370 | 0.025753462796686853 | contain |
| f | lt | 370 | 0.025753462796686853 | contain |
| f | ku | 369 | 0.02568385884318229 | contain |
| f | nu | 368 | 0.02561425488967773 | contain |
| f | rk | 368 | 0.02561425488967773 | contain |
| f | kt | 366 | 0.02547504698266861 | contain |
| f | uf | 365 | 0.025405443029164056 | contain |
| f | hn | 361 | 0.025127027215145814 | contain |
| f | nge | 351 | 0.02443098768010023 | contain |
| f | wi | 349 | 0.024291779773091108 | contain |
| f | pa | 347 | 0.024152571866081992 | contain |
| f | eb | 346 | 0.02408296791257744 | contain |
| f | aft | 345 | 0.02401336395907288 | contain |
| f | gu | 344 | 0.023943760005568315 | contain |
| f | ent | 344 | 0.023943760005568315 | contain |
| f | age | 342 | 0.0238045520985592 | contain |
| f | aus | 337 | 0.0234565323310364 | contain |
| f | lei | 336 | 0.023386928377531844 | contain |
| f | ft | 333 | 0.02317811651701817 | end |
| f | kr | 333 | 0.02317811651701817 | contain |
| f | icht | 331 | 0.023038908610009047 | contain |
| f | ul | 325 | 0.022621284888981696 | contain |
| f | lung | 322 | 0.02241247302846802 | end |
| f | her | 322 | 0.02241247302846802 | contain |
| f | re | 319 | 0.02220366116795434 | begin |
| f | er | 317 | 0.022064453260945215 | end |
| f | ad | 317 | 0.022064453260945215 | contain |
| f | ungs | 317 | 0.022064453260945215 | contain |
| f | rm | 316 | 0.021994849307440664 | contain |
| f | chu | 316 | 0.021994849307440664 | contain |
| f | tel | 316 | 0.021994849307440664 | contain |
| f | ga | 311 | 0.02164682953991787 | contain |
| f | der | 309 | 0.02150762163290875 | contain |
| f | heit | 308 | 0.02143801767940419 | end |
| f | gr | 306 | 0.021298809772395073 | contain |
| f | ot | 306 | 0.021298809772395073 | contain |
| f | uc | 306 | 0.021298809772395073 | contain |
| f | eis | 305 | 0.021229205818890512 | contain |
| f | he | 304 | 0.02115960186538596 | end |
| f | pi | 304 | 0.02115960186538596 | contain |
| f | nte | 303 | 0.0210899979118814 | contain |
| f | zei | 303 | 0.0210899979118814 | contain |
| f | fr | 300 | 0.02088118605136772 | contain |
| f | ist | 297 | 0.02067237419085404 | contain |
| f | kl | 293 | 0.02039395837683581 | contain |
| f | haf | 291 | 0.020254750469826686 | contain |
| f | su | 289 | 0.02011554256281757 | contain |
| f | gun | 289 | 0.02011554256281757 | contain |
| f | ed | 288 | 0.02004593860931301 | contain |
| f | rg | 287 | 0.01997633465580845 | contain |
| f | rie | 287 | 0.01997633465580845 | contain |
| f | gi | 286 | 0.01990673070230389 | contain |
| f | um | 286 | 0.01990673070230389 | contain |
| f | str | 286 | 0.01990673070230389 | contain |
| f | om | 285 | 0.01983712674879933 | contain |
| f | rbe | 285 | 0.01983712674879933 | contain |
| f | ha | 285 | 0.01983712674879933 | begin |
| f | th | 284 | 0.01976752279529477 | contain |
| f | sche | 283 | 0.01969791884179021 | contain |
| f | ten | 281 | 0.019558710934781096 | end |
| f | fl | 281 | 0.019558710934781096 | contain |
| f | au | 280 | 0.01948910698127653 | begin |
| f | bi | 279 | 0.019419503027771973 | contain |
| f | so | 278 | 0.01934989907426742 | contain |
| f | ue | 278 | 0.01934989907426742 | contain |
| f | gk | 277 | 0.01928029512076286 | contain |
| f | sk | 273 | 0.019001879306744626 | contain |
| f | em | 272 | 0.018932275353240064 | contain |
| f | ite | 272 | 0.018932275353240064 | contain |
| f | ho | 266 | 0.01851465163221271 | contain |
| f | im | 266 | 0.01851465163221271 | contain |
| f | ko | 266 | 0.01851465163221271 | begin |
| f | ech | 264 | 0.01837544372520359 | contain |
| f | haft | 264 | 0.01837544372520359 | contain |
| f | rn | 263 | 0.018305839771699032 | contain |
| f | nst | 263 | 0.018305839771699032 | contain |
| f | ren | 263 | 0.018305839771699032 | contain |
| f | chi | 262 | 0.018236235818194474 | contain |
| f | fi | 261 | 0.01816663186468992 | contain |
| f | gke | 259 | 0.0180274239576808 | contain |
| f | igk | 259 | 0.0180274239576808 | contain |
| f | gkei | 258 | 0.017957820004176242 | contain |
| f | igke | 258 | 0.017957820004176242 | contain |
| f | ges | 257 | 0.017888216050671674 | contain |
| f | sen | 257 | 0.017888216050671674 | contain |
| f | vo | 256 | 0.01781861209716712 | contain |
| f | zi | 255 | 0.017749008143662558 | contain |
| f | sti | 253 | 0.017609800236653442 | contain |
| f | tra | 253 | 0.017609800236653442 | contain |
| f | be | 252 | 0.017540196283148884 | end |
| f | ir | 252 | 0.017540196283148884 | contain |
| f | zu | 252 | 0.017540196283148884 | contain |
| f | aft | 250 | 0.01740098837613976 | end |
| f | br | 250 | 0.01740098837613976 | contain |
| f | uch | 250 | 0.01740098837613976 | contain |
| f | und | 249 | 0.017331384422635206 | contain |
| f | ld | 246 | 0.017122572562121532 | contain |
| f | mp | 246 | 0.017122572562121532 | contain |
| f | mu | 246 | 0.017122572562121532 | contain |
| f | chaf | 246 | 0.017122572562121532 | contain |
| f | ind | 244 | 0.01698336465511241 | contain |
| f | rte | 244 | 0.01698336465511241 | contain |
| f | po | 242 | 0.016844156748103294 | contain |
| f | dun | 242 | 0.016844156748103294 | contain |
| f | art | 238 | 0.016565740934085055 | contain |
| f | schu | 238 | 0.016565740934085055 | contain |
| f | ik | 237 | 0.016496136980580497 | end |
| f | ls | 237 | 0.016496136980580497 | contain |
| f | rd | 237 | 0.016496136980580497 | contain |
| f | fo | 236 | 0.016426533027075942 | contain |
| f | if | 236 | 0.016426533027075942 | contain |
| f | un | 236 | 0.016426533027075942 | begin |
| f | ek | 235 | 0.016356929073571374 | contain |
| f | dung | 235 | 0.016356929073571374 | contain |
| f | da | 234 | 0.01628732512006682 | contain |
| f | est | 234 | 0.01628732512006682 | contain |
| f | che | 233 | 0.016217721166562258 | end |
| f | ma | 228 | 0.015869701399039458 | begin |
| f | era | 226 | 0.01573049349203035 | contain |
| f | ieru | 226 | 0.01573049349203035 | contain |
| f | an | 226 | 0.01573049349203035 | begin |
| f | alt | 224 | 0.015591285585021231 | contain |
| f | bu | 223 | 0.01552168163151667 | contain |
| f | up | 220 | 0.01531286977100299 | contain |
| f | arb | 218 | 0.015173661863993874 | contain |
| f | pe | 216 | 0.015034453956984757 | end |
| f | bl | 214 | 0.01489524604997564 | contain |
| f | ahr | 214 | 0.01489524604997564 | contain |
| f | zeit | 214 | 0.01489524604997564 | contain |
| f | mo | 213 | 0.014825642096471081 | contain |
| f | nf | 213 | 0.014825642096471081 | contain |
| f | ine | 212 | 0.014756038142966518 | contain |
| f | schi | 212 | 0.014756038142966518 | contain |
| f | ei | 212 | 0.014756038142966518 | begin |
| f | age | 211 | 0.014686434189461962 | end |
| f | pf | 211 | 0.014686434189461962 | contain |
| f | ran | 211 | 0.014686434189461962 | contain |
| f | end | 210 | 0.014616830235957404 | contain |
| f | nh | 209 | 0.014547226282452844 | contain |
| f | auf | 209 | 0.014547226282452844 | contain |
| f | dung | 208 | 0.014477622328948284 | end |
| f | ht | 207 | 0.014408018375443725 | end |
| f | id | 207 | 0.014408018375443725 | contain |
| f | ef | 206 | 0.014338414421939168 | contain |
| f | stel | 206 | 0.014338414421939168 | contain |
| f | ei | 205 | 0.014268810468434609 | end |
| f | ke | 205 | 0.014268810468434609 | end |
| f | hau | 205 | 0.014268810468434609 | contain |
| f | se | 204 | 0.014199206514930047 | begin |
| f | cht | 203 | 0.014129602561425491 | end |
| f | ber | 203 | 0.014129602561425491 | contain |
| f | tin | 203 | 0.014129602561425491 | contain |
| f | ang | 202 | 0.01405999860792093 | contain |
| f | hun | 202 | 0.01405999860792093 | contain |
| f | lag | 202 | 0.01405999860792093 | contain |
| f | sp | 202 | 0.01405999860792093 | begin |
| f | el | 201 | 0.013990394654416372 | end |
| f | ap | 201 | 0.013990394654416372 | contain |
| f | bs | 201 | 0.013990394654416372 | contain |
| f | lic | 201 | 0.013990394654416372 | contain |
| f | ak | 200 | 0.013920790700911812 | contain |
| f | hw | 200 | 0.013920790700911812 | contain |
| f | tei | 200 | 0.013920790700911812 | contain |
| f | ka | 200 | 0.013920790700911812 | begin |
| f | ug | 199 | 0.013851186747407252 | contain |
| f | rsc | 199 | 0.013851186747407252 | contain |
| f | arbe | 199 | 0.013851186747407252 | contain |
| f | rsch | 199 | 0.013851186747407252 | contain |
| f | no | 196 | 0.013642374886893576 | contain |
| f | bei | 196 | 0.013642374886893576 | contain |
| f | chl | 196 | 0.013642374886893576 | contain |
| f | enz | 196 | 0.013642374886893576 | contain |
| f | rat | 196 | 0.013642374886893576 | contain |
| f | nde | 195 | 0.013572770933389015 | end |
| f | chw | 195 | 0.013572770933389015 | contain |
| f | ert | 195 | 0.013572770933389015 | contain |
| f | ba | 195 | 0.013572770933389015 | begin |
| f | rl | 194 | 0.013503166979884457 | contain |
| f | lich | 194 | 0.013503166979884457 | contain |
| f | kun | 193 | 0.0134335630263799 | contain |
| f | stu | 191 | 0.01329435511937078 | contain |
| f | le | 191 | 0.01329435511937078 | begin |
| f | op | 190 | 0.013224751165866222 | contain |
| f | lan | 190 | 0.013224751165866222 | contain |
| f | hm | 189 | 0.013155147212361662 | contain |
| f | sel | 189 | 0.013155147212361662 | contain |
| f | rec | 187 | 0.013015939305352544 | contain |
| f | ben | 186 | 0.012946335351847985 | contain |
| f | cke | 185 | 0.012876731398343428 | contain |
| f | men | 185 | 0.012876731398343428 | contain |
| f | hung | 185 | 0.012876731398343428 | contain |
| f | den | 184 | 0.012807127444838869 | contain |
| f | erb | 183 | 0.012737523491334307 | contain |
| f | mer | 183 | 0.012737523491334307 | contain |
| f | bes | 182 | 0.01266791953782975 | contain |
| f | hal | 182 | 0.01266791953782975 | contain |
| f | lie | 182 | 0.01266791953782975 | contain |
| f | ner | 182 | 0.01266791953782975 | contain |
| f | gen | 181 | 0.012598315584325193 | end |
| f | og | 181 | 0.012598315584325193 | contain |
| f | gie | 181 | 0.012598315584325193 | contain |
| f | fe | 181 | 0.012598315584325193 | begin |
| f | haft | 180 | 0.01252871163082063 | end |
| f | chr | 180 | 0.01252871163082063 | contain |
| f | rau | 180 | 0.01252871163082063 | contain |
| f | cher | 180 | 0.01252871163082063 | contain |
| f | nsc | 179 | 0.012459107677316072 | contain |
| f | tsc | 179 | 0.012459107677316072 | contain |
| f | wei | 179 | 0.012459107677316072 | contain |
| f | nsch | 179 | 0.012459107677316072 | contain |
| f | tsch | 179 | 0.012459107677316072 | contain |
| f | ab | 179 | 0.012459107677316072 | begin |
| f | rz | 178 | 0.012389503723811512 | contain |
| f | eil | 178 | 0.012389503723811512 | contain |
| f | ern | 178 | 0.012389503723811512 | contain |
| f | ien | 178 | 0.012389503723811512 | contain |
| f | schw | 178 | 0.012389503723811512 | contain |
| f | pr | 176 | 0.012250295816802394 | begin |
| f | wa | 176 | 0.012250295816802394 | begin |
| f | rh | 175 | 0.012180691863297836 | contain |
| f | erk | 175 | 0.012180691863297836 | contain |
| f | kti | 175 | 0.012180691863297836 | contain |
| f | vor | 175 | 0.012180691863297836 | contain |
| f | we | 175 | 0.012180691863297836 | begin |
| f | ob | 174 | 0.012111087909793277 | contain |
| f | esc | 174 | 0.012111087909793277 | contain |
| f | its | 174 | 0.012111087909793277 | contain |
| f | esch | 174 | 0.012111087909793277 | contain |
| f | vo | 174 | 0.012111087909793277 | begin |
| f | dr | 172 | 0.011971880002784156 | contain |
| f | rbei | 171 | 0.0119022760492796 | contain |
| f | ser | 170 | 0.011832672095775041 | contain |
| f | gel | 169 | 0.011763068142270482 | contain |
| f | beit | 169 | 0.011763068142270482 | contain |
| f | er | 169 | 0.011763068142270482 | begin |
| f | ise | 168 | 0.011693464188765922 | contain |
| f | uer | 168 | 0.011693464188765922 | contain |
| f | eits | 168 | 0.011693464188765922 | contain |
| f | chn | 167 | 0.011623860235261362 | contain |
| f | nie | 167 | 0.011623860235261362 | contain |
| f | schl | 167 | 0.011623860235261362 | contain |
| f | he | 167 | 0.011623860235261362 | begin |
| f | nl | 166 | 0.011554256281756804 | contain |
| f | the | 166 | 0.011554256281756804 | contain |
| f | oc | 165 | 0.011484652328252245 | contain |
| f | lage | 165 | 0.011484652328252245 | contain |
| f | hte | 164 | 0.011415048374747685 | contain |
| f | kra | 164 | 0.011415048374747685 | contain |
| f | unge | 164 | 0.011415048374747685 | contain |
| f | fah | 163 | 0.011345444421243129 | contain |
| f | pro | 163 | 0.011345444421243129 | contain |
| f | tin | 162 | 0.011275840467738569 | end |
| f | bo | 162 | 0.011275840467738569 | contain |
| f | chte | 162 | 0.011275840467738569 | contain |
| f | nb | 161 | 0.01120623651423401 | contain |
| f | nhe | 161 | 0.01120623651423401 | contain |
| f | vers | 161 | 0.01120623651423401 | contain |
| f | ub | 159 | 0.011067028607224891 | contain |
| f | erg | 159 | 0.011067028607224891 | contain |
| f | han | 158 | 0.010997424653720332 | contain |
| f | lin | 158 | 0.010997424653720332 | contain |
| f | hen | 157 | 0.010927820700215772 | contain |
| f | nhei | 157 | 0.010927820700215772 | contain |
| f | nter | 157 | 0.010927820700215772 | contain |
| f | ate | 156 | 0.010858216746711212 | contain |
| f | rech | 156 | 0.010858216746711212 | contain |
| f | fer | 155 | 0.010788612793206654 | contain |
| f | sic | 155 | 0.010788612793206654 | contain |
| f | sich | 155 | 0.010788612793206654 | contain |
| f | ank | 154 | 0.010719008839702095 | contain |
| f | anz | 154 | 0.010719008839702095 | contain |
| f | hre | 154 | 0.010719008839702095 | contain |
| f | kon | 154 | 0.010719008839702095 | contain |
| f | len | 154 | 0.010719008839702095 | contain |
| f | tur | 154 | 0.010719008839702095 | contain |
| f | me | 154 | 0.010719008839702095 | begin |
| f | hk | 153 | 0.010649404886197537 | contain |
| f | iche | 153 | 0.010649404886197537 | contain |
| f | in | 153 | 0.010649404886197537 | begin |
| f | na | 153 | 0.010649404886197537 | begin |
| f | erl | 152 | 0.010579800932692977 | contain |
| f | fahr | 152 | 0.010579800932692977 | contain |
| f | pl | 151 | 0.010510196979188416 | contain |
| f | sl | 151 | 0.010510196979188416 | contain |
| f | igu | 151 | 0.010510196979188416 | contain |
| f | per | 151 | 0.010510196979188416 | contain |
| f | raf | 151 | 0.010510196979188416 | contain |
| f | rst | 151 | 0.010510196979188416 | contain |
| f | ur | 150 | 0.01044059302568386 | end |
| f | ade | 150 | 0.01044059302568386 | contain |
| f | res | 150 | 0.01044059302568386 | contain |
| f | hung | 149 | 0.0103709890721793 | end |
| f | od | 149 | 0.0103709890721793 | contain |
| f | sb | 148 | 0.01030138511867474 | contain |
| f | enh | 148 | 0.01030138511867474 | contain |
| f | ew | 147 | 0.010231781165170182 | contain |
| f | rw | 147 | 0.010231781165170182 | contain |
| f | chk | 147 | 0.010231781165170182 | contain |
| f | ehr | 147 | 0.010231781165170182 | contain |
| f | las | 147 | 0.010231781165170182 | contain |
| f | tre | 147 | 0.010231781165170182 | contain |
| f | mi | 147 | 0.010231781165170182 | begin |
| f | ein | 147 | 0.010231781165170182 | begin |
| f | fe | 146 | 0.010162177211665622 | end |
| f | ahl | 146 | 0.010162177211665622 | contain |
| f | tze | 146 | 0.010162177211665622 | contain |
| f | for | 145 | 0.010092573258161064 | contain |
| f | tro | 145 | 0.010092573258161064 | contain |
| f | la | 145 | 0.010092573258161064 | begin |
| f | re | 144 | 0.010022969304656505 | end |
| f | ins | 144 | 0.010022969304656505 | contain |
| f | acht | 144 | 0.010022969304656505 | contain |
Here we hope to find our rules.
The sequence Value matched can appear at the end (end) or anywhere (contain) in the word.
In the previous textbook heuristics table we had a number of rules per gender:
- Masculine: 40 rules
- Feminine: 15 rules
- Neutral: 13 rules
- Total (40 + 15 + 13) = 68 rules
A new set of rules
In our quest to reduce cognitive load we are looking for better rules than the ones you have seen. They are pretty accurate. Can we reduce the number of rules to memorize? Armed with the big table of characters groups we can start looking.
First try: best 20 rules based on ending
Let’s try to find the best rules from all the permutations possible.
As a first exploration we will focus on ending in rules and try with a maximum number of 20 rules.
| Masculine | Feminine | Neutral |
|---|---|---|
| -ung | -hen | |
| -it | -chen | |
| -eit | -ren | |
| -te | ||
| -ion | ||
| -se | ||
| -ie | ||
| -le | ||
| -tion | ||
| -rin | ||
| -rung | ||
| -ge | ||
| -erin | ||
| -keit | ||
| -ne | ||
| -de | ||
| -tung |
20 best ending in rules. If it ends in the value we classify it as in that gender.
No masculine rule made it to the top 20.
Results best 20
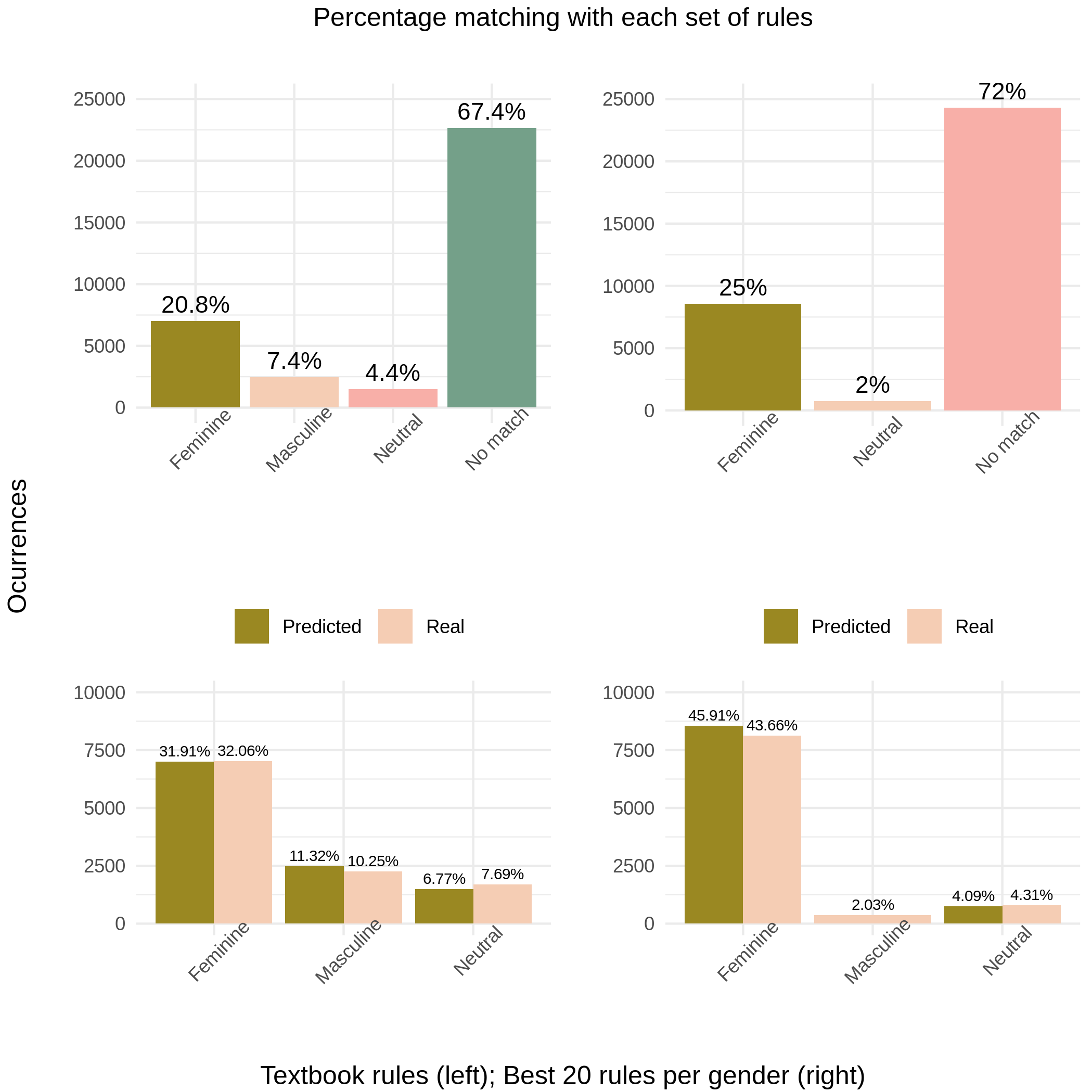
It is pretty accurate
| Textbook % match | Ours % match | Difference match |
|---|---|---|
| 0.27 | 0.26 | 0.02 |
| Textbook f % correct | Textbook f % correct.1 | Difference f % correct |
|---|---|---|
| 0.64 | 0.64 | -0.28 |
| Textbook m % correct | Textbook m % correct.1 | Difference m % correct |
|---|---|---|
| 0.23 | 0.23 | 0.23 |
| Textbook n % correct | Textbook n % correct.1 | Difference n % correct |
|---|---|---|
| 0.14 | 0.14 | 0.05 |
2% improvement over the textbook.
We can also see how each gender m, f and n perform individually with textbook rules vs ours.
Both the graph and the numbers give us the same insights. Our first guess, with 20 rules already performs 2% better than the baseline!
In search of even better rules
Until now we checked only 20 rules. Why 20? since the textbook had (as seen before):
- Masculine: 40 rules
- Feminine: 15 rules
- Neutral: 13 rules
- Total (40 + 15 + 13) = 68 rules
20 was just a guess to explore the data.
What is the optimal number of ending in rules that gives as the greatest accuracy? Let’s find out.
Best rules based on begins, contains or ending
Until now we checked only 20 rules per gender, where the rule is “word ends in” -ung, -er, etc. mimicking the rules from the textbook.
Probably ending in is easier to remember, but we do not need to limit ourselves to this rule.
It might be that contains (anywhere in the word) produces an easier to remember rule with the same or better accuracy.
We will run the best rules from 1 rule to 68 (the textbook number of rules) and see how accurate they are.
Results from 1 to 68 rules
| Textbook % match | Ours % match | Difference match | Rule # | Match type |
|---|---|---|---|---|
| 0.27 | 0.45 | -0.17 | 68 | end |
| 0.27 | 0.45 | -0.17 | 67 | end |
| 0.27 | 0.44 | -0.17 | 66 | end |
| 0.27 | 0.44 | -0.17 | 65 | end |
| 0.27 | 0.44 | -0.17 | 64 | end |
| 0.27 | 0.44 | -0.16 | 63 | end |
| 0.27 | 0.43 | -0.16 | 62 | end |
| 0.27 | 0.43 | -0.15 | 60 | end |
| 0.27 | 0.43 | -0.15 | 58 | end |
| 0.27 | 0.43 | -0.15 | 59 | end |
| 0.27 | 0.43 | -0.16 | 61 | end |
| 0.27 | 0.42 | -0.14 | 55 | end |
| 0.27 | 0.42 | -0.15 | 56 | end |
| 0.27 | 0.42 | -0.15 | 57 | end |
| 0.27 | 0.41 | -0.14 | 54 | end |
| 0.27 | 0.41 | -0.13 | 53 | end |
| 0.27 | 0.4 | -0.13 | 51 | end |
| 0.27 | 0.4 | -0.12 | 49 | end |
| 0.27 | 0.4 | -0.13 | 50 | end |
| 0.27 | 0.4 | -0.13 | 52 | end |
| 0.27 | 0.39 | -0.12 | 47 | end |
| 0.27 | 0.39 | -0.12 | 46 | end |
| 0.27 | 0.39 | -0.12 | 48 | end |
| 0.27 | 0.38 | -0.11 | 45 | end |
| 0.27 | 0.38 | -0.1 | 44 | end |
| 0.27 | 0.37 | -0.1 | 43 | end |
| 0.27 | 0.37 | -0.1 | 42 | end |
| 0.27 | 0.36 | -0.09 | 40 | end |
| 0.27 | 0.36 | -0.09 | 41 | end |
| 0.27 | 0.35 | -0.08 | 38 | end |
| 0.27 | 0.35 | -0.08 | 39 | end |
| 0.27 | 0.35 | -0.07 | 37 | end |
| 0.27 | 0.34 | -0.07 | 36 | end |
| 0.27 | 0.34 | -0.07 | 35 | end |
| 0.27 | 0.33 | -0.06 | 34 | end |
| 0.27 | 0.33 | -0.06 | 33 | end |
| 0.27 | 0.33 | -0.05 | 32 | end |
| 0.27 | 0.32 | -0.05 | 31 | end |
| 0.27 | 0.31 | -0.04 | 30 | end |
| 0.27 | 0.31 | -0.04 | 29 | end |
| 0.27 | 0.3 | -0.03 | 28 | end |
| 0.27 | 0.29 | -0.02 | 26 | end |
| 0.27 | 0.29 | -0.01 | 25 | end |
| 0.27 | 0.29 | -0.02 | 27 | end |
| 0.27 | 0.28 | -0.01 | 23 | end |
| 0.27 | 0.28 | -0.01 | 24 | end |
| 0.27 | 0.27 | 0.0 | 22 | end |
| 0.27 | 0.26 | 0.02 | 65 | contain |
| 0.27 | 0.26 | 0.01 | 66 | contain |
| 0.27 | 0.26 | 0.01 | 67 | contain |
| 0.27 | 0.26 | 0.01 | 68 | contain |
| 0.27 | 0.26 | 0.01 | 21 | end |
| 0.27 | 0.26 | 0.02 | 20 | end |
| 0.27 | 0.26 | 0.02 | 19 | end |
| 0.27 | 0.25 | 0.02 | 64 | contain |
| 0.27 | 0.25 | 0.02 | 62 | contain |
| 0.27 | 0.25 | 0.02 | 63 | contain |
| 0.27 | 0.25 | 0.03 | 60 | contain |
| 0.27 | 0.25 | 0.03 | 61 | contain |
| 0.27 | 0.24 | 0.03 | 59 | contain |
| 0.27 | 0.24 | 0.03 | 18 | end |
| 0.27 | 0.24 | 0.04 | 58 | contain |
| 0.27 | 0.23 | 0.05 | 16 | end |
| 0.27 | 0.23 | 0.04 | 57 | contain |
| 0.27 | 0.23 | 0.04 | 17 | end |
| 0.27 | 0.23 | 0.05 | 55 | contain |
| 0.27 | 0.23 | 0.04 | 56 | contain |
| 0.27 | 0.23 | 0.05 | 14 | end |
| 0.27 | 0.23 | 0.05 | 15 | end |
| 0.27 | 0.22 | 0.05 | 54 | contain |
| 0.27 | 0.22 | 0.05 | 52 | contain |
| 0.27 | 0.22 | 0.06 | 51 | contain |
| 0.27 | 0.22 | 0.05 | 53 | contain |
| 0.27 | 0.21 | 0.07 | 47 | contain |
| 0.27 | 0.21 | 0.06 | 13 | end |
| 0.27 | 0.21 | 0.06 | 49 | contain |
| 0.27 | 0.21 | 0.06 | 50 | contain |
| 0.27 | 0.21 | 0.06 | 12 | end |
| 0.27 | 0.21 | 0.06 | 48 | contain |
| 0.27 | 0.21 | 0.06 | 11 | end |
| 0.27 | 0.2 | 0.07 | 45 | contain |
| 0.27 | 0.2 | 0.07 | 10 | end |
| 0.27 | 0.2 | 0.07 | 46 | contain |
| 0.27 | 0.2 | 0.07 | 44 | contain |
| 0.27 | 0.2 | 0.07 | 9 | end |
| 0.27 | 0.19 | 0.08 | 42 | contain |
| 0.27 | 0.19 | 0.08 | 41 | contain |
| 0.27 | 0.19 | 0.08 | 43 | contain |
| 0.27 | 0.18 | 0.09 | 40 | contain |
| 0.27 | 0.18 | 0.09 | 8 | end |
| 0.27 | 0.18 | 0.1 | 39 | contain |
| 0.27 | 0.17 | 0.11 | 36 | contain |
| 0.27 | 0.17 | 0.1 | 37 | contain |
| 0.27 | 0.17 | 0.1 | 38 | contain |
| 0.27 | 0.17 | 0.11 | 7 | end |
| 0.27 | 0.17 | 0.11 | 35 | contain |
| 0.27 | 0.16 | 0.11 | 34 | contain |
| 0.27 | 0.16 | 0.11 | 33 | contain |
| 0.27 | 0.16 | 0.11 | 32 | contain |
| 0.27 | 0.16 | 0.11 | 31 | contain |
| 0.27 | 0.16 | 0.11 | 30 | contain |
| 0.27 | 0.16 | 0.11 | 29 | contain |
| 0.27 | 0.16 | 0.11 | 28 | contain |
| 0.27 | 0.16 | 0.11 | 27 | contain |
| 0.27 | 0.15 | 0.12 | 6 | end |
| 0.27 | 0.15 | 0.12 | 26 | contain |
| 0.27 | 0.15 | 0.12 | 25 | contain |
| 0.27 | 0.15 | 0.12 | 24 | contain |
| 0.27 | 0.15 | 0.12 | 23 | contain |
| 0.27 | 0.15 | 0.13 | 22 | contain |
| 0.27 | 0.14 | 0.13 | 21 | contain |
| 0.27 | 0.13 | 0.14 | 20 | contain |
| 0.27 | 0.13 | 0.14 | 5 | end |
| 0.27 | 0.13 | 0.15 | 19 | contain |
| 0.27 | 0.12 | 0.15 | 4 | end |
| 0.27 | 0.12 | 0.16 | 18 | contain |
| 0.27 | 0.11 | 0.17 | 15 | contain |
| 0.27 | 0.11 | 0.17 | 16 | contain |
| 0.27 | 0.11 | 0.17 | 17 | contain |
| 0.27 | 0.1 | 0.18 | 2 | end |
| 0.27 | 0.1 | 0.18 | 3 | end |
| 0.27 | 0.1 | 0.18 | 14 | contain |
| 0.27 | 0.08 | 0.19 | 10 | contain |
| 0.27 | 0.08 | 0.19 | 11 | contain |
| 0.27 | 0.08 | 0.19 | 9 | contain |
| 0.27 | 0.08 | 0.19 | 13 | contain |
| 0.27 | 0.08 | 0.19 | 12 | contain |
| 0.27 | 0.07 | 0.2 | 6 | contain |
| 0.27 | 0.07 | 0.2 | 7 | contain |
| 0.27 | 0.07 | 0.2 | 8 | contain |
| 0.27 | 0.07 | 0.2 | 1 | end |
| 0.27 | 0.05 | 0.22 | 5 | contain |
| 0.27 | 0.04 | 0.23 | 4 | contain |
| 0.27 | 0.02 | 0.25 | 1 | contain |
| 0.27 | 0.02 | 0.25 | 3 | contain |
| 0.27 | 0.02 | 0.25 | 2 | contain |
We take the best rules from 1 rule to 68 rules and measure their accuracy vs the baseline (“Ours % match” vs “Textbook % match”)
Below we can see this data in a more intuitive way:
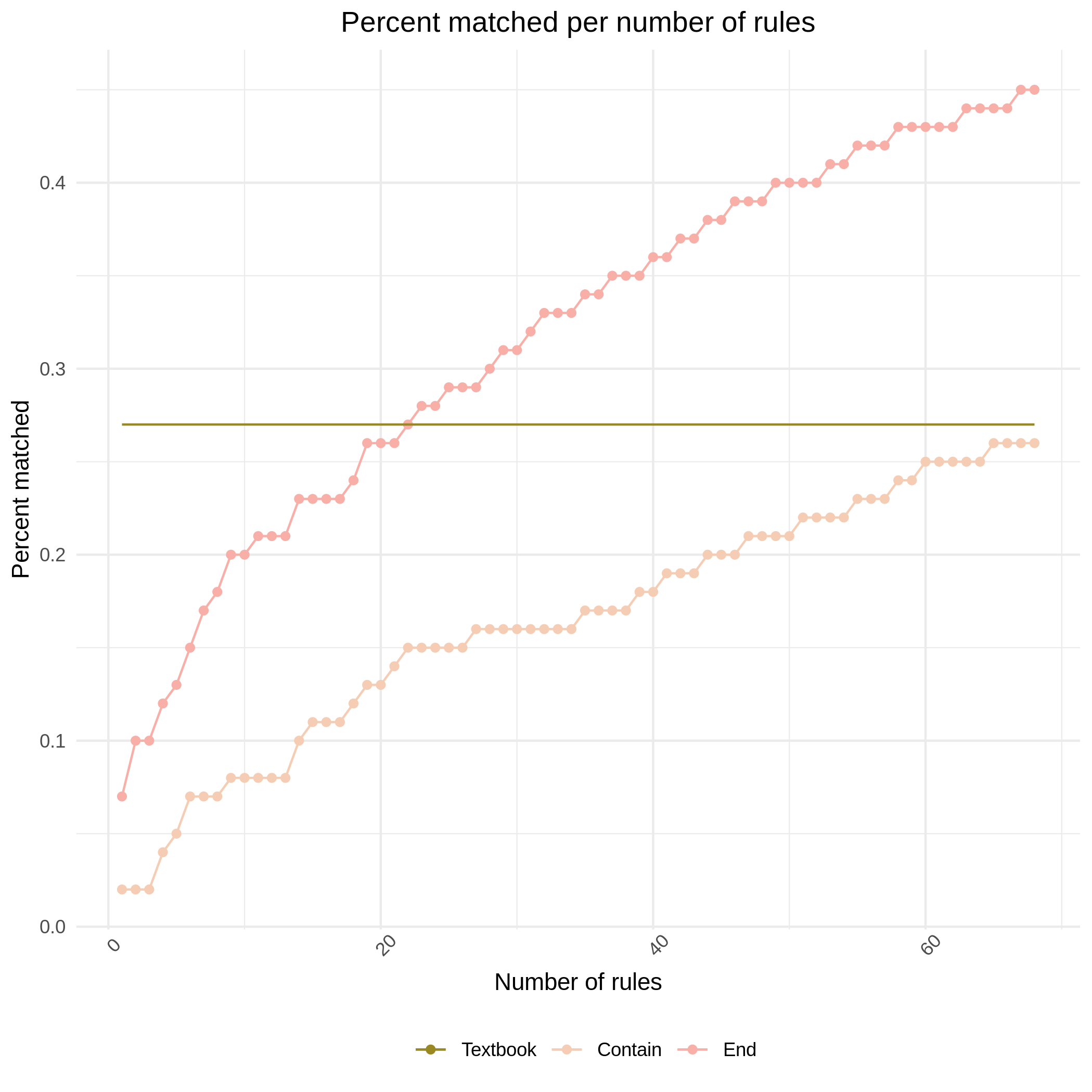
The letters at the end of a word (ending) predict the gender better than in other positions (contain)
We can see clearly:
- Textbook rules match
27%of the time. Ending rules are more accurate thatcontainrules.- With just
22rules we can achieve the same accuracy as with textbook’s68rules.
Or, alternatively:
- with
68rules (same as textbook) we can increase the accuracy from27%to45%.
The new rules
In the previous section we calculated the different tradeoffs between accuracy and number of rules to remember. How many rules are you willing to memorize?
If you only remember one rule
You cannot be bothered, tempus fugit. If you can only learn one rule, learn this one.
| Masculine | Feminine | Neutral |
|---|---|---|
| -ung |
You will be right 7% of the time.
To be 20% accurate: 10 rules
Even a broken clock is right twice a day. If you are happy with a set of rules correct 20% of the time use these 10 rules:
| Masculine | Feminine | Neutral |
|---|---|---|
| -ung | -hen | |
| -it | ||
| -eit | ||
| -te | ||
| -ion | ||
| -se | ||
| -ie | ||
| -le | ||
| -tion |
Same accuracy, less to memorize (recommended)
To guess the same amount of words as with the textbook rules: 27%.
You will have to memorize a bit less6: instead of the 68 rules before, only the 22 below:
| Masculine | Feminine | Neutral |
|---|---|---|
| -tz | -ung | -hen |
| -ck | -it | -chen |
| -eit | -ren | |
| -te | ||
| -ion | ||
| -se | ||
| -ie | ||
| -le | ||
| -tion | ||
| -rin | ||
| -rung | ||
| -ge | ||
| -erin | ||
| -keit | ||
| -ne | ||
| -de | ||
| -tung |
Maximum accuracy: 68 rules
Only the best is enough. Perfection is not the enemy of the good for you, but the only good. Then, study these 68 rules — same number as before, from our textbook — for a correct guess 45% of the time, versus a now pale 27%.
| Masculine | Feminine | Neutral |
|---|---|---|
| -tz | -ung | -hen |
| -ck | -it | -chen |
| -st | -eit | -ren |
| -ler | -te | -ld |
| -ag | -ion | -al |
| -or | -se | -sen |
| -sch | -ie | -ben |
| -mus | -le | -rn |
| -kt | -tion | -ium |
| -her | -rin | -et |
| -ang | -rung | -ken |
| -ug | -ge | -em |
| -rt | -erin | -aus |
| -atz | -keit | -haus |
| -aum | -ne | -icht |
| -pf | -de | -ern |
| -ger | -tung | -men |
| -ft | -eln | |
| -lung | -eld | |
| -heit | ||
| -he | ||
| -be | ||
| -aft | ||
| -ik | ||
| -che | ||
| -pe | ||
| -age | ||
| -dung | ||
| -ke | ||
| -ei | ||
| -nde | ||
| -haft |
Coda
Thanks for reading until the very end! If you are learning german, I hope the new 22 rules make it slightly easier.
If you know of another set of rules to guess the gender of a noun in german I would be happy to hear from them. Viel Spaß! :)
Thanks for reading
Footnotes
-
You can find the data on the github repository ↩
-
Will somebody think of our friend cognitive load. ↩
-
After looking in the dusty Studio D A1: Deutsch als Fremdsprache and Studio D A2: Deutsch als Fremdsprache I could not find gender heuristics explicitely in the text (the teacher must have explained them outside of the book) I found a good list in Gramática funcional del alemán p.215 ( ISBN: 84-7960-095-0) ↩
-
For instance, words containing
enmatch in20-36%all three genders.Gender matched Value matched Num matched Percent matched Match type n en 2819 0.357468 contain m en 2369 0.208191 contain f en 3178 0.221201 contain Not very useful rules: they match everything. The percentage of the same gender matched by the rule. If the rule applies to
neutral, it matches n% of the total of words withneutralgender. The percentage ranges from 0.0 to 1.0 — i.e. 0.03 represents 3 % — -
El saber no ocupa lugar, knowledge takes no room/space. A nice spanish saying, maybe from somebody who did not often have to cram for an exam. ↩